| ||||||||||||||||||||||||||||||||||||

1. Введение. Обоснование актуальности темы.Появление вычислительных систем с базами данных привело к изменению прежней парадигмы обработки данных, в которой для каждого приложения определялись и поддерживались собственные наборы данных, на новую, в которой все данные определялись и поддерживались централизовано. Технология распределенных бах данных, получившая в настоящее время широкое распространение, способствует обратному переходу от централизованной обработки данных к децентрализованной. Создание технологии систем управления распределенными базами данных является одним из самых больших достижений в области баз данных. Основной причиной разработки систем, использующих базы данных, является стремление интегрировать все обрабатываемые в организации данные в единое целое и обеспечить к ним контролируемый доступ. На практике создание компьютерных сетей приводит к децентрализации обработки данных. Децентрализованный подход, по сути, отражает организационную структуру компании, логически состоящую из отдельных подразделений, отделов, проектных групп, которые физически распределены по разным офисам, отделениям, предприятиям или филиалам, причем каждая отдельная единица имеет дело с собственным набором обрабатываемых данных. Разработка распределенных баз данных, отражающих организационные структуры предприятий, позволяет сделать данные, поддерживаемые каждым из существующих подразделений, общедоступным, обеспечив при этом их сохранение именно в тех местах, где они чаще всего используются. Подобный подход расширяет возможности совместного использования информации, одновременно повышая эффективность доступа к ней. Распределенная база данных (РБД) представляет собой сложную динамическую систему, в которой выполняется множество запросов к распределенным данным, производится обновления множества копий, расположенных на разных узлах компьютерной сети. Производительность РБД зависит не только от параметров технических средств (серверов, каналов связи), но и от того, насколько рационально распределены данные в системе. Поэтому задачи оптимизации РБД с целью обеспечения высокой эффективности их работы возникают и являются актуальными как при проектировании компьютерных информационных систем, так и при модернизации существующих систем. Среди основных преимуществ распределенной базы данных можно выделить следующие:
Первым преимуществом РБД является отображение структуры организации. Крупные организации, как правило, имеют множество отделений, которые могут находиться в разных концах страны и даже за ее пределами. Используемая этой компанией база данных должна быть распределена между ее отдельными офисами. В каждом отделении компании может поддерживаться база данных, содержащая сведения о персонале, сдаваемых в аренду объектах недвижимости, которыми занимаются сотрудники данного отделения, а также о клиентах, которые владеют или желают получить в аренду эти объекты. В подобной базе данных персонал отделения сможет выполнять необходимые ему локальные запросы. Руководству компании может потребоваться выполнять глобальные запросы, предусматривающие получение доступа к данным ,сохраняемых во всех существующих отделениях. Вторым преимуществом является повышение доступности данных. В централизованных СУБД отказ центрального компьютера вызывает прекращение функционирования всей СУБД. Отказ одного из узлов СУРБД или линии связи между узлами сделает недоступным только лишь некоторые узлы, тогда как вся система в целом сохранит свою работоспособность. Распределенные СУБД проектируются таким образом, чтобы обеспечивать функционирование системы несмотря на подобные отказы. Если выходит из строя один из узлов, система сможет перенаправить запросы к отказавшему узлу в адрес другого узла. Если организована репликация данных, в результате чего данные и их копии будут размещены на более чем одном узле, отказ отдельного узла или соединительной связи между узлами не приведет к недоступности данных в системе. Если данные размещены на самом нагруженном узле, то развертывание распределенной СУБД может способствовать повышению скорости доступа к базам данных. Более того, поскольку каждый узел работает только с частью базы данных, уровень использования центрального процессора и служб ввода/вывода может оказаться ниже, чем в случае централизованной СУБД. В распределенной среде расширение существующей системы осуществляется намного проще. Добавление в сеть нового узла не оказывает влияние на функционирование уже существующих. Перегрузка из-за увеличения размера базы данных обычно устраняется путем добавления в сеть новых вычислительных мощностей и устройств дисковой памяти. В централизованной СУБД рост размера базы данных может потребовать замены и оборудования и используемого программного обеспечения. вверх2. Цели и задачи работы.Целью магистерской работы является повышение производительности работы распределенных баз данных компьютерных информационных систем путем оптимизации распределения данных по узлам компьютерной сети. Для достижения поставленной цели необходимо решить следующие задачи: 1. Изучить особенности выполнения распределенных запросов и распространений обновлений в MS SQL Server. 2. Создать математическую модель распределенной базы данных с учетом особенностей выполнения запросов и распространения обновлений. 3. Определить набор параметров распределенной базы данных, которые необходимо получить для вычисления эффективности функционирования распределенной базы данных. Разработать базу данных параметров РБД и статистической информации о процессах выполнения запросов и распространения обновлений. 4. Разработать инструментальные средства сбора статистической информации. 5. Модифицировать алгоритм оптимизации распределения данных по узлам компьютерной информационной сети. вверх3. Предполагаемая научная новизна.С целью получения субоптимального решения в задаче оптимального распределения данных по узлам компьютерной сети необходимо учесть все особенности функционирования РБД, разработанной на конкретной СУБД. В результате выполнения работы планируется, во-первых, изучив все особенности работы РБД в MS SQL Server (распространение обновлений и выполнение запросов), а также, определив параметры РБД, которые можно собрать или получить с помощью существующих программных средств (SQL Profiler), разработать математическую модель оптимального распределения файлов по узлам компьютерной сети с целью минимизации общего времени выполнения запросов и распространения обновлений. Данная модель должна учитывать такие особенности распределенных баз данных, как фрагментацию и репликацию. Во-вторых, в результате того, что важными при получении субоптимального решения являются исходные данные, предполагается разработать инструментальное средство сбора статистической информации о процессах, происходящих при работе РБД ( о временных параметрах распространения обновлений и выполнения запросов). В-третьих, разработать модификацию генетического алгоритма, позволяющего найти решение оптимального распределения данных по узлам компьютерной сети. вверх4. Предполагаемая практическая ценность.В результате выполнения магистерской работы планируется получить результаты, которые повысят производительность работы распределенных баз данных за счет уменьшения времени выполнения запросов и обработки обновлений путем оптимального распределения данных по узлам компьютерной сети. Точность полученных результатов оптимального распределения предполагается повысить также за счет использования точных исходных параметров работы РБД, определяемых с помощью разработанных инструментальных средств и за счет использования генетического алгоритма. вверх5. Обзор существующих исследований и разработок.Распределенная база данных – это набор логически связанных между собой разделяемых данных (и их описаний), которые физически распределены в некоторой компьютерной сети. Распределенная система управления базами данных – это программный комплекс, предназначенный для управления распределенными базами данных и позволяющий сделать распределенность информации прозрачной для конечного пользователя. Система управления распределенными базами данных состоит из единой логической базы данных, разделенной на некоторое количество фрагментов. Каждый фрагмент базы данных сохраняется на одном или нескольких компьютерах, которые соединены между собой линиями связи и каждый из которых работает под управлением отдельной СУБД (рисунок 1). Любой из узлов способен независимо обрабатывать запросы пользователей, требующие доступа к локально сохраняемым данным, а также способен обрабатывать данные, сохраняемые на других узлах. 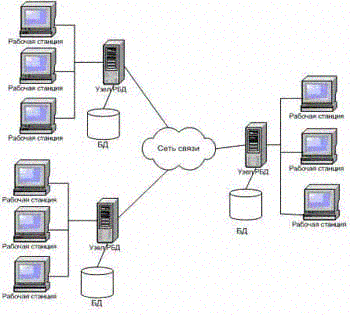
Рисунок 1 - Пример типичной системы распределенных баз данных. Для конечного пользователя распределенность системы должна быть совершенно прозрачна. Другими словами, от пользователей должен быть скрыт тот факт, что распределенная база данных состоит из нескольких фрагментов, которые могут размещаться на различных компьютерах и для которых, возможно, организована служба репликации данных. Назначение обеспечения прозрачности состоит в том, чтобы распределенная система внешне выглядела как и централизованная. В некоторых случаях, это требование называется основным принципом построения распределенных СУБД. Отношения, принадлежащие распределенной базе данных, могут быть разделены на вертикальные и горизонтальные фрагменты. Фрагменты могут храниться на разных узлах. Фрагментация желательна для повышения производительности системы. В этом случае данные могут храниться в том месте, где они чаще всего используются, что позволяет достичь локализации большинства операций и уменьшения сетевого трафика. Существует два основных вида фрагментации: горизонтальная и вертикальная (анимация 1); они соответствуют реляционным операциям сокращения и проекции. В общем виде фрагмент можно представить в виде результата произвольного сочетания операций сокращения и проекции. Анимация 1 - Пример фрагментации. Восстановление исходной переменной отношения из ее фрагментов выполняется с помощью соответствующих операций соединения и объединения. Система поддерживает репликацию данных, если данная хранимая переменная отношения может быть представлена несколькими отдельными копиями, или репликами, которые хранятся на нескольких отдельных узлах (рисунок 2). 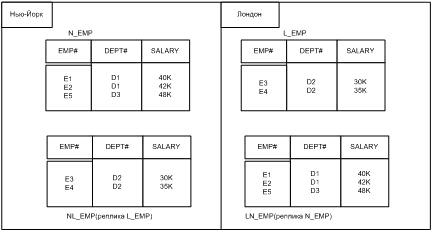
Рисунок 2 - Пример репликации. Репликация желательна, по крайней мере, по двум причинам. Во-первых, она способна обеспечить более высокую производительность, поскольку приложения смогут обрабатывать локальные копии вместо того, чтобы устанавливать связь с удаленными узлами. Во-вторых, наличие репликации может также обеспечить более высокую степень доступности, поскольку любой реплицируемый объект остается доступным для обработки, пока хотя бы одна реплика в системе остается доступной. Главным недостатком репликации является то, что если реплицируемый объект обновляется, то все его копии должны быть обновлены. Таким образом, рассмотрение организации РБД показало, то данные физически распределяются по узлам компьютерной информационной системы при помощи фрагментации и репликации, а основными процессами, протекающими в таких системах, являются выполнение пользовательских запросов и распространения обновлений. Рассмотрим существующие модели оптимального распределения данных по узлам компьютерной сети. Весомый вклад по вопросам оптимизации РБД внес Цегелик Г.Г. В своей книге «Системы распределенных баз данных» он представил модели оптимального размещения файлов по узлам сети с различными критериями эффективности. В качестве критериев эффективности им было предложено использовать средний объем пересылаемых данных по линиям связи при обработке запросов и распространении обновлений, общую стоимость трафика, порожденного функционированием распределенной вычислительной системы в течение единицы времени, эксплуатационную стоимость сети. В качестве примера рассмотрим модель оптимального размещения файлов по компьютерной сети с критерием эффективности – средний объем пересылаемых данных по линиям связи при обработке запросов и распространении обновлений. Рассмотрим вычислительную сеть, каждый узел которой состоит из ЭВМ, терминальных устройств и аппаратуры передачи данных. Предположим, что запрос, поступающий на терминальное устройство любого узла, предполагает доступ к определенному файлу распределенной базы данных, и объем запросного и корректирующего сообщения к одному и тому же файлу зависит от узла, из которого лоно поступило. Будем считать, что схема обработки запросов состоит в следующем. Запрос, инициированный на терминале,поступает во входную очередь соответствующего узла. Процессор ЭВМ обрабатывает запросы в порядке их поступления. Если копия нужного файла содержится в локальной базе данных узла, на терминал которого поступил запрос, то запрос обрабатывается и результата выводится на этот терминал. Если копия нужного файла не содержится в локальной базе данных узла, то сначала по справочнику локальной базы данных определяется узел, содержащий копию нужного файла. Затем запрос пересылается в этот узел, там обрабатывается и ответ поступает в первоначальный узел. Порядок обслуживания запросов не влияет на объем пересылаемых данных по каналам связи. Корректирующие сообщения обслуживаются в порядке их очереди. Однако по сравнению с запросными сообщениями, они имеют наивысший приоритет обслуживания. В процессе обслуживания запросных и корректирующих сообщений в течение каждой единицы времени по каналам связи пересылается некоторый объем данных, зависящий от распределения копий файлов по локальным базам данных. Чем меньший объем пересылаемых данных по каналам связи за единицу времени, тем выше скорость обработки сообщений. Пусть n - число узлов сети; m - число независимых файлов, входящих в распределенную базу данных; Kj - j-й узел сети; Fi - i-й файл распределенной базы данных;
Li - объем i-го файла; bj- объем памяти узла Kj, предназначенный для размещения файлов; yi - число копий i-го файла (yi-заданная величина,1<=yi<=n); xij(
Интенсивность
нуждающихся в пересылке. Если положить
то средний объем данных, необходимых для пересылки при обработке корректирующего сообщения в системе равен,
Интенсивность
где
Таким образом, математическая модель задачи оптимального распределения копий файлов по узлам вычислительной сети для критерия оптимальности средний объем пересылаемых данных по линиям связи при обработке запросного и корректирующего сообщения будет следующей: требуется найти минимум линейной функции L=V+V' при ограничениях
Для улучшения производительности системы в качестве дополнительного условия может быть использовано ограничение на ожидаемое время выполнения запроса из каждого узла. Действительно, пусть aijs - ожидаемое время, необходимое для выполнения запроса, инициированного в узле Kj , к файлу Fi , который содержится в узле Ks ; Tij - максимально допустимое время выполнения запроса к файлу Fi , инициированного в узле Kj . Тогда между величинами aijs и Tij имеет место соотношение
для j<>s, 1<=i<=m . Чтобы из этого соотношения получить ограничение, следует величины aijs выразить через переменные xij . В общем случае топологии сети это сделать очень трудно. И только при использовании целого ряда допущений, налагаемых на характеристики сети, можно найти простые выражения значений aijs через xij . К недостаткам разработанных моделей можно отнести то, что они содержат ряд ограничений и упрощений, не отражают такую особенность РБД, как фрагментация, а также то, что они статичны и не учитывают динамику происходящих в системе процессов. Что касается методов, применявшихся для оптимизации РБД, – метод ветвей и границ, математическое программирование – они не дали положительных результатов, так как для реальных сложных компьютерных информационных систем с РБД размерность задачи велика, что требует значительных затрат времени и вычислительных ресурсов. Поэтому для данной задачи целесообразно использовать генетические алгоритмы, реализующие направленный случайный поиск, основанный на механизмах природной эволюции. Таким образом, несмотря на проведенные ранее исследования вопросы моделирования и оптимизации РБД компьютерных информационных систем не получили окончательного решения, используемые модели и методы имеют ряд недостатков, что обусловило необходимость их дальнейшего совершенствования. Не менее важным вопросом, как было сказано выше, является предоставление наиболее точных исходных данных. Реализация любой математической модели оптимального размещения файлов РБД по узлам компьютерной сети требует ряда информационных массивов исходных данных, значительная часть которых может быть получена лишь в усредненном или приближенном виде. Это такие характеристики, как интенсивность запросов, время пересылки и обработки запросов, объемы запросов и ответов на запросы. Точность собранной статистической информации будет решающим образом влиять на конечный результат реализации выбранной математической модели и, следовательно, на производительность системы, работающей с РБД. Для получения достоверных числовых данных необходимо выяснить цикличность обращения информации в системе. Этот период может колебаться для систем различных приложений от одного дня до квартала. При дальнейшей обработке собранной информации необходимо учитывать как среднестатистические обращения, так и стохастические всплески активности. Числовые характеристики времени обработки, объема пересылок и вероятностей обращения необходимо рассчитывать с учетом поправки на пиковые ситуации, чтобы защитить систему от значительных задержек во время наиболее интенсивных загрузок. Кроме перечисленных выше характеристик в процессе работы с оптимизируемой базой данных необходимо накапливать информацию о виде запроса (чтение, поиск, корректировка), имени файла, к которому выдан запрос, номере узла, с которого выдан запрос, времени реального ответа. В настоящее время вопрос сбора параметров работы РБД остается не решенным. Выходом из сложившейся ситуации на данный момент является проведение анализа работы РБД. Собирается и анализируется информация о том, как часто выполняются запросы, вносятся изменения в таблицы РБД, а затем на основании собранных сведений, вычисляются входные данные для нахождения оптимального решения на основании математической модели. Очевидно, что анализ работы РБД не позволяет получать точные данные. Для получения точных данных необходимо исследовать с помощью программных средств работу реальной РБД. вверх6. Планируемые собственные результаты.В результате выполнения работы планируется получить математическую модель оптимального распределения данных по узлам сети с критерием эффективности – среднее время обработки запросов и распространения обновлений в системе в единицу времени, учитывающие все особенности функционирования РБД, разработанных в MS SQL Server; разработать модификацию генетического алгоритма для решения задачи оптимизации РБД; разработать инструментальное средство сбора информации об основных параметрах работы РБД. вверх7. Заключение.В настоящее время в результате развития компьютерных информационных систем, большое применение получили распределенные базы данных. РБД повышают производительность работы системы за счет распределения данных по множеству узлов при помощи репликации и фрагментации. Для достижения наилучшего результата требуется оптимально разместить файлы и их копии по узлам сети. Моделям оптимального размещения файлов по узлам сети посвящен ряд научных работ, однако многие из них содержат ряд ограничений и упрощений, не отражают особенности РБД, такие как репликация и фрагментация, а также не учитывают динамику происходящих в системе процессов. Существующие методы оптимизации требуют значительных затрат времени и вычислительных ресурсов для нахождения субоптимального решения вследствие больших размеров РБД. Нерешен вопрос и относительно представления исходных данных для решения задачи. Таким образом, целью магистерской работы является повышение производительности работы РБД путем оптимизации распределения данных по узлам компьютерной сети. Для этого предполагается исследовать работу РБД, разработанную в MS SQL Server(механизм выполнения запросов и распространения обновлений), реализовать инструментальное средство сбора исходной статистической информации, разработать соответствующую математическую модель с критерием эффективности – среднее время обработки запросов и распространения обновлений, поступивших в систему в единицу времени, а также модифицировать генетический алгоритм для решения задачи на основании описанной математической модели. вверх8. Список литературы.1. Цегелик Г.Г. Системы распределенных баз данных. – Львов: Свит, 1990. – 168 с. 2. Дейт К.Дж. Введение в системы баз данных, 8-е издание.: Пер. с англ. – М.: Издательский дом «Вильямс»,2005. –1328 с. 3. Оутей М., Конте П. Эффективная работа: SQL Server 2000. – СПб.: Питер; К.: Издательская группа BHV, 2002. – 992 с. 4. Колесников Д.Г. Оптимизация распределения информационных файлов в сетях ЭВМ с параллельной обработкой//Диссертация на соискание ученой степени кандидата технических наук.- Ростов-на-Дону,1999. - http://megapolis-tnk.ru/kdg/thesis.htm 5. М. Тамер Оззу, Патрик Валдуриз. Распределенные и параллельные системы баз данных// Системы управления базами данных, #04/1996 - http://www.osp.ru/dbms/1996/04/4.htm |
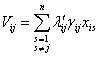
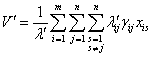 .
.
|