| ДонНТУ | Портал магистров ДонНТУ | Главная | Реферат | Ссылки | Отчет о поиске | Индивидуальное задание |
Назад в Библиотеку
A Combination Fingerprint Classifier
Andrew Senior.
Источник:
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 23, NO. 10, OCTOBER 2001
Перевод с английского языка Петровой Т. В.
Комбинированный Классификатор Отпечатков пальцевAndrew Senior.Институт инженеров по электротехнике и электроникеКраткий обзор – Классификация отпечатков пальцев – это важный метод индексации для любой крупномасштабной системы распознавания по отпечаткам пальца или базы данных как метод для уменьшения количества отпечатков пальцев, которое должно искаться для выполнения этапа сопоставления. Отпечатки пальца обычно классифицированы в крупные категории, которые базируются на глобальных характеристиках. Эта статья описывает новые методы классификации, использующие скрытые модели Маркова (СММ) и деревья решений для распознавания структуры выступа на отпечатке, без необходимости обнаруживать особые точки. Методы сравниваются и объединяются со стандартными алгоритмами классификации отпечатков пальцев и результаты объединения представлены при использовании стандартной базы данных отпечатков пальцев. Статья также описывает метод достижения любого уровня точности, требуемого системой, жертвуя эффективностью классификатора. Была достигнутая более высокая точность комбинированного классификатора, чем при тестировании двух современных систем при тех же условиях. Ключевые слова – Классификатор отпечатков пальцев Henry, скрытые модели Маркова, деревья решений, нейронные сети, база данных NIST. 1. ВВЕДЕНИЕ Классификация отпечатков пальца является одной из важнейших частей любой системы распознавания по отпечаткам пальцев. Разделение отпечатков пальцев на группы в широком смысле аналогичных образцов допускает регистрироваться и осуществлять поиск в больших базах данных отпечатков пальцев за короткое время. К настоящему времени интерес к классификации отпечатков пальцев стимулируется ее использованием в системах автоматической идентификации по отпечаткам пальцев (AFIS). В AFIS целью является нахождение соответствия для входного образца отпечатка пальца в базе данных занесенных отпечатков, которая, возможно, содержит много миллионов образцов. Классификация, использованная в AFIS для уменьшения размера пространства поиска, осуществляет отнесение отпечатка к какому-либо классу перед этапом нахождения полного соответствия. Наиболее широко используемыми системами классификации отпечатков пальцев являются системы Henry и их вариации. Примеры пяти основных классов отпечатков систем Henry представлены на рисунке 1.
Рисунок 1 - Примеры пяти основных классов отпечатков пальцев с отмеченной частотой их встречаемости. (a) левая петля, (b) правая петля, (c) завиток, (d) дуга, (e) полусфера Много предшествующих авторов разработали автоматизированные системы классификации отпечатков пальцев, используя широкое разнообразие методов. Cappelli и другие [2] провели современный обзор целого ряда методов, которые были использованы для классификации, и раздел 8 данной статьи представляет результаты других авторов. Большинство автоматических систем используют классы Генри и это важно для существующих баз данных AFIS и систем, которые требуют совместимости с человеческими классификациями, или из-за накопленных (существующих) данных, или, потому что некоторое ручное вмешательство необходимо в процессе, требуя использования интерпретированных человеком классов. Было проверено разнообразие подходов для классификации, самый фундаментальный - синтаксический анализ относительного (взаимного) расположения и количества ядро и дельта точек на отпечатке. Ядро и дельта точки, показанные на Рисунке 1, - это особые точки вдоль линии выступа. Поиск этих точек на изображении - это сложная задача обработки изображений, особенно если эти изображения плохого качества, но если они найдены надежно, то классификация простая [3], [4]. Maio и Maltoni [5] использовали структурный анализ направления выступов на отпечатке, без необходимости обнаружения ядро и дельта точек. Blue и другие. [6] и Candela и другие. [7] использовали расположение ядра в центре их схемы представления, которая основана на анализе главных компонентов (PCA) направлений выступа, а затем они используют разнообразие классификаторов. Halici и Ongun [8] используют сходный подход, но классификацию производят с помощью отображения с самоорганизацией (способ обучения нейронной сети при недостаточном количестве данных); и Jain и другие [9] также использовали ядро для трансляционной инвариантности, затем использовалось представление фильтра Gabor, и классификатор «К» - ближайших соседей. Для ситуаций, где нет никакой необходимости использовать существующие классы, некоторые исследователи разработали системы, которые зависят от генерируемых машиной классов или обходятся без классов и вместе и используют "непрерывную" классификацию [2], [10], [8], [11]. Здесь критерием является не принадлежность к классам Генри, а лишь непротиворечивость среди классификаций различных отпечатков с одного пальца. Отпечатки пальца представлены точками в пространстве признаков, в котором производится некоторое измерение расстояния. Тестовые отпечатки пальца сопоставляются против всех тех в базе данных, которые дают ошибку в пределах некоторого радиуса тестового отпечатка. Увеличивая радиус, классификация может быть сделана в некотором смысле точной, сокращая ошибки путем увеличения размера пространства поиска и сокращая время поиска. Эта статья описывает комбинацию новых подходов классификации отпечатков пальца, используя систему Генри. Описанная система разработана, чтобы оперировать как с снятыми сканером, так и снятыми вручную отпечатками пальцев, где некоторая структурная информация, используемая другими системами (как например положение дельта точки), возможно, не доступна на изображении отпечатка пальца. Описанная система проверена на специальной базе данных изображений отпечатков пальцев NIST 4 [12] и результаты представлены. Далее описан метод измерения эффективности алгоритма классификации, позволяя произвести принципиальное сравнение этого алгоритма с предыдущими опубликованными в работах. Окончательно, метод для достижения произвольной точности описан, позволяя классификатору Генри использоваться с приспосабливаемыми непрерывными классификаторами. Этот метод ставит точность против эффективности классификатора, позволяя несовершенному классификатору использоваться в реальной системе, при сохранении всех преимуществ традиционной системы Генри. Используемый здесь подход представляет собой комбинацию классификаторов, каждый из которых использует различные признаки для осуществления классификации и дает различные ошибки на тестовых данных. Описано два новых классификатора, используя двумерные скрытые модели Маркова (СММ) и деревья решений. В добавление к этому показываем, что эти классификаторы хорошо решают задачу классификации и без необходимости информации об ядро/дельта точках. Эта статья показывает, что комбинация классификаторов обеспечивает прорыв вперед для улучшения классификации отпечатков пальцев. Классификаторы проверены в изоляции и в комбинации с Вероятностным классификатором нейронной сети и исследованием псевдовыступа от системы PCASYS, описанной Candela и другие. [7]. Эксперименты целиком выполняются на дискретной классификации Генри, но система могла бы быть расширена до непрерывной классификации или классификации с неконтролируемыми кластерами, используя такие методы как, неконтролируемая кластеризация СММ с K-средними [13]. Следующие разделы описывают классификатор СММ (ранее описанный в [14]), классификатор дерева решений, и классификаторы PCASYS. В разделе 5 описывается классификация, основанная на выходах этих классификаторов, на их объединении, чтобы улучшить точность. Раздел 6 описывает меру эффективности классификатора и показывает, как может быть достигнута произвольная эффективность. Раздел 7 представляет результаты для классификаторов и их комбинации, и в разделе 8 эти результаты сравнивают с ранее опубликованными результатами. 2. КЛАССИФИКАЦИИЯ С ПОМОЩЬЮ СКРЫТЫХ МОДЕЛЕЙ МАРКОВА Скрытые модели Маркова (СММ) являются формой стохастического конечного автомата и хорошо подходят для распознавания образов и успешно применяются для распознавания речи [15], [16], а так же решают другие проблемы. Они подходят для решения проблемы рассматриваемой в данной статье из-за своей способности классифицировать образцы, базирующиеся на большом количестве характеристик, число которых является переменным и, которые имеют определенные типы глубинной структуры, особенно если эта структура дает в результате стационарные распределения характеристик над немного пространственным или временным периодом. Такая структура обнаружена в отпечатках пальцев, в которых ориентация выступа, расстояния и кривизна, главным образом, только медленно изменяется через отпечаток. В отпечатке пальца базовая классовая информация может заключатся в синтаксическом анализе особых точек, но может быть также найдена на общем образце выступов – путь неспециализированной человеческой классификации отпечатков. СММ способны статистически смоделировать различные структуры образцов выступа путем накопления данных (признаков) со всего отпечатка, не рассчитывая на извлечение особых точек. 2.1 Извлечение выступа Система имеет дело с изображениями отпечатков пальцев, сохраненными как массивы значений уровней яркости и полученные сканером или камерой или с отпечатка пальца чернилами на бумаге или непосредственно с пальца («живое сканирование»). В большинстве работ этой статьи база данных NIST-4 [12], содержащая изображения отпечатков пальцев, используется с тех пор, как была снабжена большим количеством отпечатков пальцев (4000), помеченные метками класса. Кроме того, использована часть базы данных NIST-9. Признаки, предусмотренные для распознавания, основаны на характеристиках пересечений выступов с набором опорных линий, которые положены через изображение отпечатка пальца. Для того чтобы находить позиции выступа используется ряд методов обработки изображений [17], которые приведены далее:
2.2 Выделение признаков Дано каркасное изображение выступов, параллельно проведены опорные линии через изображение под углом ф, как показано на рисунке 2, и каждая следует поочерёдно. Для каждого пересечения опорной линии с выступом сгенерирован признак.
Рисунок 2 - Пример отпечатка пальца, показывающий горизонтальные опорные линии (ф = 0). Каждый признак состоит из набора замеров, выбранных для характеристики поведения выступа и его развития в точке пересечения:
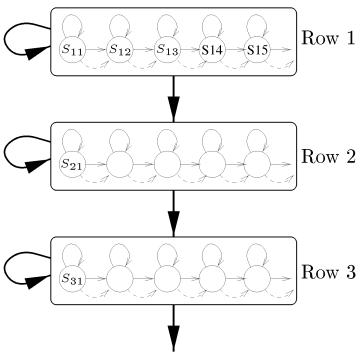
Характеристики угла (2) могут содержать аналогичную информацию для вычисления грубого направления поля на этапах предварительной обработки этой системы и используются другими системами как характеристика, установленная для классификации [7]. Тем не менее, это представление допускает более высокое разрешение представления отпечатков пальцев и содержит больше информации для представления отпечатка (например, расстояние выступа и кривизна). Дальнейшие измерения могут также быть взяты в каждой точке. Измерения каждой характеристики охарактеризованы блоком данных и блоками данных, Rik для i-той опорной линии коллективно охарактеризованы строкой, Ri, упорядочение в которой сохранено. Для каждой ориентации ф опорных линий получено отдельное представление Rф = { Ri, Vi} отпечатков. В этих исследованиях используются только горизонтальные и вертикальные линии, давая характеристики Rh и Rv, соответственно, но другие углы могут учитывать дальнейшую информацию, которую нужно захватывать. 2.3 Скрытые модели Маркова Обычно, СММ - одномерные структуры, пригодные для анализа временных данных. Здесь данные двумерные, но процесс выделения признаков может также быть описан как одномерный массив одномерных строковых процессов. Таким образом, мы можем применить «двумерную скрытую модель Маркова», подобную Agazzi [18], которая состоит из вложенных рядов моделей в пределах целой модели отпечатка, как показано в Рисунке 3.
Рисунок 3 - Схема двумерной структуры СММ, показывающей три ряда моделей, состоящих из пяти состояний каждая, формирующие глобальную модель для одного класса. Для классификации создается модель Mc для каждого класса c и выбирается класс с максимальной вероятностью после расчета вероятности данных R, получается модель: argmaxcP(R|Mc). 2.3.1 Моделирование рядов Для того чтобы упростить анализ модели, сначала рассматривается моделирование строковой модели – отдельного ряда данных отпечатка пальца. Каждая строковая модель - стандартная СММ и состоит из множества состояний, которые моделируют небольшие стационарные (неподвижные) области подряд. Любой ряд Ri должен быть сгенерирован переходом строкового автомата из состояния к состоянию, производя блоки данных в наблюдаемом порядке на каждом переходе, с Sijk состояния k-той последовательности, посредством чего Mi производит Ri (k соответствует времени во временных СММ). Переходы состояний управлялись вероятностями P(Sijk|Sijk-1), обученными определенным ограничениям: состояние должно монотонно увеличиваться Sijk >= Sijk', для k > k' и оно возможно должно пропускать состояния на крае отпечатка. Из-за природы процесса печати, посредством чего, особенно для мазков (снятых чернильным методом отпечатков), предполагается, что краевые области отпечатка пальца будут потеряны, но центральные области всегда будут присутствовать, только состояния на крае отпечатка могут быть пропущены. Это эффективно ограничивает начальное состояние распределения P(Sijko). Вероятность эмиссии блока данных смоделирована смесью диагональных ковариаций многомерных распределений Гаусса. Таким образом, для любого блока данных Rik, возможно должна вычисляться вероятность P(Rik|Sijk) этого, происходя в любом состоянии Sijk. С этой вероятностью, для любой строковой модели, вероятность любой колонки может быть аппроксимирована максимальной вероятностью любого состояния ряда, выравнивающей (выстраивающей в линию) характеристики и состояния, вычисленные как результат вероятностей блока данных и вероятности перехода для состояния ряда:
Модели инициализированы использованием равной длины выравнивания с блоками данных, равномерно распределенными через состояния модели. После оценки начальных значений параметра, используя плавное выравнивание равной длины [19], используется выравнивание Viterbi для нахождения максимальной вероятности выравнивания блоков данных с состояниями, которые были использованы для переобучения. Около двух итерации обучения необходимы для достижения хороших результатов классификации. 2.3.2 Глобальные модели Глобальная модель такая же как и строковая модель, за исключением того, что ее состояния являются строковыми моделями, а ее блоки данных являются целыми (полными) рядами. Таким образом, для каждой модели c:
где S' - выравнивание, определяющее какую строковую модель MSk' моделирует ряд данных Rk. 2.4 Составные классификаторы СММ Для каждой ориентации опорных линий может быть сделан отдельный классификатор. Так как ошибки различных классификаторов будут различны, комбинация их оценок может дать лучшую точность. Обозначим Mch, Mcv, модели класса c, обученные с вертикальными и горизонтальными характеристиками, соответственно, и, принимая во внимание независимость, вероятность данных запишется как:
Объединение составных классификаторов освещается более подробно в Разделе 5.3. 3. КЛАССИФИКАТОР ДЕРЕВЬЯ РЕШЕНИЙ |





![]()
ВВЕРХ
| ДонНТУ | Портал магистров ДонНТУ | Главная | Реферат | Библиотека | Ссылки | Отчет о поиске | Индивидуальное задание |