
Abstract
Сontents
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research, schedulable results
- 3. Review of researches and development
- 3.1 Review of international sources
- 3.2 Review of national sources
- 3.3 Review of local sources
- 4. Overview of basic algorithm of constructing of a straight line in three-dimensional space
- 5. Further modification of algorithm. The use of CUDA technology
- 6. Implementation of the device of constructing of a straight line on FPGA
- Conclusion
- References
Introduction
The main means of interaction between computers and humans today are display units. Thus the results of computer processing of some data are presented to the user. Leaving aside the withdrawal of alphanumeric information, more focused on the support of linguistic communication, display data in the form of natural or man–made graphic images has become now the most common way of bringing large amounts of information to people. [1]
The displays, allowing to display visual information in “real” three–dimensional space (3D–displays), represent one of the most interesting directions in development of technology of information display. Now new approaches to creation of 3D–displays roughly develop. At the same time pursued the main goal — the opportunity to provide a person (the operator) a greater amount of visual information in real time, without overloading his senses and brain. Such displays have wide perspectives for application in systems of automated management, creation of trainers. Modern classification [2] of 3D displaying devices separates special branch of systems that are built using the means of volumetric technologies. Such devices imply absence of special auxiliary accessories for the operator, all equipment for division of stereoscopic pairs of images is “naturally” built–in in the display.
The wide circulation of similar displays requires not only creations of actually displaying devices but also development of methods of three–dimensional expansion of scenes and algorithms of functioning of its elements. Feature of devices of display on the basis of volume technologies is existence of the volume voxel storage device — analog of raster memory of two–dimensional devices of display. In case of generation of the three–dimensional image in voxel memory software create the voxelmodel of real objects consisting of set of three–dimensional graphic primitives: segments of three–dimensional straight lines, three–dimensional planes, arcs, circles, spherical triangles, ellipsoids, etc. [1]
1. Theme urgency
During constant increase in interest to visualization of three–dimensional images need for development and creation of methods of three–dimensional expansion of scenes and algorithms of functioning of its elements. Unlike normal (2D) displays for which methods of raster expansion of graphic primitives are developed rather well and passed wide approbation of practicians, three–dimensional expansion practically isn’t worked and requires researches both in the direction actually expansion methods and in the direction of optimization of these methods from of hardware–software and their hardware implementation. On the basis of these algorithms in the subsequent more difficult graphic objects, their compositions will be built, and also there will be a formation of difficult scenes. The modern development of a science and technique allows to use also along with development of effective solutions different tools, namely a parallel approach. Therefore in this work the new and progressive technology of multisequencing on graphic processors is considered and applied.
At the moment the majority of algorithms and approaches in computer graphics are oriented on the solution of problems, concerning visualization in space of customary display units: monitors, data plotters, panel of creeping line and other. More narrow sphere is display of graphic images and elements of scenes by means of volume displays. The hardware changeover of the volume display unit already ready software products displaying a separate part of a three–dimensional continuous Euclidean space (MatLab, MathCAD, SciDAVis) can appear. It allows to solve a problem of check of results of the developed algorithm in a type of unavailability of the material resources because of its high cost and absence adequately checked and safe hardware decisions. Special attention also is given to optimization of operation of algorithms of a three–dimensional graphics of view of expended time for scene generation and of the hardware expenses that often is a defining factor of a choice of strategy of the solution of an objective.
2. Goal and tasks of the research, schedulable results
The aim of the study is to develop methods for parallelization of algorithms of decomposition voxel graphics primitives for volumetric 3D display devices.
Main objectives of research:
- Development of methods for generating voxel representation of a line segment in 3D space.
- Research of methods of parallel generation on architecture of CUDA.
- Research of methods of parallel generation on a cluster.
- Development of the specialized device of generation of segments of straight lines in 3D space on the basis of the FPGA technology.
Object of research: process of three–dimensional sampling of standard graphic primitives of computer graphics.
Subject of research: methods and hardware and software of creation of volume three–dimensional graphics displays.
As part of the master plan to get the actual scientific results in the following areas:
- Getting the best method of generating voxel representation of a line segment in 3D space.
- Developing an algorithm generating a line segment in 3D space on a multi–threaded architecture of the GPU CUDA.
- Development of the specialized device of generation of segments of straight lines in 3D space on the basis of the FPGA technology.
For the experimental assessment of the received theoretical results and formation of the base of the subsequent researches as practical results implementation of algorithm of generation of segments of straight lines in 3D space in the following directions is planned:
- The program which generates the coordinates of the entire set of voxels involved in the decomposition of three–dimensional voxel line segment in 3D space of the display. The experiments and measurements consisting of multiple launches program for execution and further analysis of the temporal parameters and characteristics which indicate the accuracy of voxel decomposition, were based on a computer that has the following characteristics: Intel(R) Core(TM)2 Duo CPU E4600 2.40GHz, 2.40GHz, 1,99Gb RAM.
- For software and hardware improvements introduced by the structure of the algorithm is tested on the basis of its architecture CUDA which involves the use of the GPU as a basis for resource calculations. Experiments aimed at the parallelization of the program, conducted on the basis of a computer that has the following characteristics: Intel(R) Core(TM)2 Duo CPU E4600 2.40GHz, 2.40GHz, 1,99Gb RAM.
- Hardware implementation of the algorithm will be based on FPGA Spartan–3E from Xilinx [3–4] by immersion of the algorithm on the board. Thus, it is an attempt to create a specialized device designed to solve a particular problem — voxel decomposition of an entity.
Figure 1 explains the steps of generation algorithm development and testing process.
3. Review of researches and development
The three–dimensional voxel graphics is for today quite hot and interesting topic therefore the researches connected to this subject, aren’t a novelty. There is the significant amount of articles in which text authors open different scopes of a voxel graphics and also consider the problems getting in the way its implementations. These articles in the most part are foreign and have the general character. However the specialized development directed on generation of graphic primitives in space of three–dimensional displays, are adequately new and low–probed knowledge domain.
3.1 Review of international sources
Andres M. Trianon in his article on the subject of three–dimensional devices of display considers the main types of volume displays, their advantages and shortcomings, and also ways of further development. [5]
Vincent Breton in his article consideres applications of voxel graphics in medicine during the diagnostics process. In Russian. [6]
Shalamov А.V. and Mazein P.G. consider voxel graphics as an application for popular CAD systems. In Russian. [7]
3.2 Review of national sources
Baskkov Е.А., Avksentieva O.A., Al–Oraiqat Anas М. in their article consider the methods of graphic primitives construction in space of three-dimensional displays. In Russian. [1]
Bashkov Е.А., Avksentieva O.A., Al–Oraiqat Anas М., Dubrovina О.D. in their article consider algorithmic base which is connected to construction of straight line parts for 3D displays. In Russian. [8]
Bashkov Е.А., Hartchenko N.О., Avksentieva O.A. in their article consider the method of expansion of an arbitrary voxel volumetric arc for 3D displays. [9]
3.3 Review of local sources
Master Hartchenko N.O. considers the problem of voxel expansion of arbitrary arc for volume 3D displays. [10]
Master Hromova Е.N. considers the problem of net model creation of object with complex shape using the random set of points in 3D space. In Russian. [11]
Master Zaharov S.S. considers the problem of natural phenomenon computer modeling and sky and clouds construction. In Russian. [12]
4. Overview of basic algorithm of constructing of a straight line in three–dimensional space
The task of a raster line segment expansion is formulated as the problem of determining the set of voxels that are in 3D space of the display which belong to the initial and final generation of voxels each of which (except for the initial and final) has two and only two neighboring voxel the center of each of which lies on the minimum distance from the line and their number in the set is minimal. The essence of the algorithm is that at some stage there is some generation of the resulting voxel sequence that is required to determine the next voxel raster expansion. To do this are seven adjacent voxels of applicants in a direction which is determined by the direction vector line segment. Calculate the distance between their centers and a given straight line. Next in the sequence is defined as a voxel–candidate with a minimum distance to the line. In this way we construct a set of voxels in the expansion of the raster line segment.
On the basis of the above algorithm is implemented the program. The results of the program are shown below in Figure 1. Calculated set of voxel coordinates have been wrote to text file which had special structure. After this the set of obtained voxels could be processed using 3D visualization program. SciDAVis had been used to display the set of voxels in part of Euclidean space which is displayed by three-dimensional displaying device.
Figure 1 — The result of visualization of three–dimensional line which is initialized by random parameters (visualization environment — SciDAVis software package)
15 frames. Frames delay time = 250 msec.
Animation size: 448px х 280px. File size: 93.8 Kbytes. Created using MP GIF Animator.
5. Further modification of algorithm. The use of CUDA technology
“CUDA (Compute Unified Device Architecture) is a parallel computing architecture developed by NVIDIA. CUDA is the computing engine in NVIDIA graphics processing units (GPUs) that is accessible to software developers through variants of industry standard programming languages. Programmers use “C for CUDA” (C with NVIDIA extensions and certain restrictions), compiled through a PathScale Open64 C compiler, to code algorithms for execution on the GPU. CUDA architecture shares a range of computational interfaces with two competitors — the Khronos Group’s Open Computing Language and Microsoft’s DirectCompute. Third party wrappers are also available for Python, Perl, Fortran, Java, Ruby, Lua, MATLAB and IDL, and native support exists in Mathematica. CUDA gives developers access to the virtual instruction set and memory of the parallel computational elements in CUDA GPUs. Using CUDA, the latest NVIDIA GPUs become accessible for computation like CPUs. Unlike CPUs however, GPUs have a parallel throughput architecture that emphasizes executing many concurrent threads slowly, rather than executing a single thread very quickly.” [13]
When using the GPU developers are several types of memory: registers, local, global, shared, constant and texture memory. Each of these memory types has a specific purpose, which is driven by its technical parameters (speed, level of access for reading and writing) [14]. The hierarchy of memory types is presented in Figure 2.
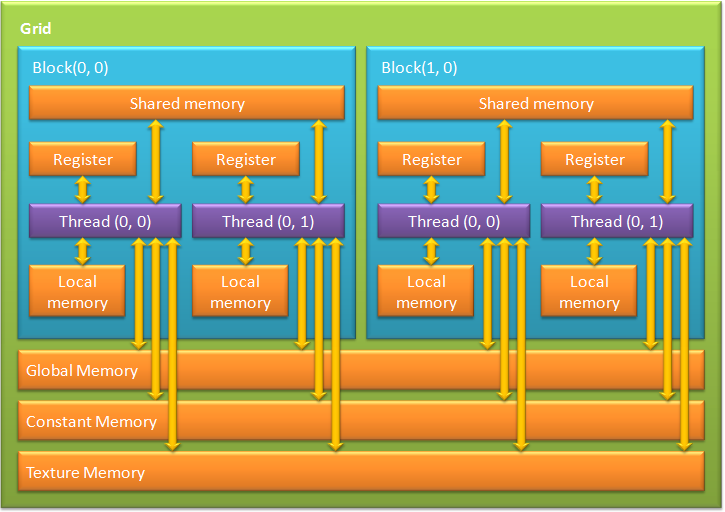
Figure 2 — Types of memory in CUDA
During software–hardware optimization process CUDA architecture had been used as high–speed parallel system which can execute parts of developed code in parallel [15]. As we can modify our code which is written using standard C language according to CUDA restrictions and requirements [16–18] obtained algorithm had been translated to special C language dialect. There were some complexities during program development which were dedicated to searching of code blocks that could be translated to parallel language [19–20]. These blocks had been found and realized taking into account cycles amount minimization.
One of the main tasks that appeared during program development was to find the method which could help to calculate programs time duration. Standard GetTickCount() function showed incorrect results and it was decided to refuse from its using. Standard CUDA architecture method Compute Visual Profiler became the most comfortable method of programs time delay calculation. As I increased an amount of cycles to test line generation application the degree of parallelism increased too. According to amount of testing launches an acceleration which had been shown by CUDA was from 4 up to 8 times. These results were predictable because the degree of parallelism was equal to amount of neighboring voxels for each voxel. So the calculation of next voxel coordinates in voxel decomposition had been done in parallel.
6. Implementation of the device of constructing of a straight line on FPGA
The most effective element basis of the last years reads programmable logic integrated circuits (PLIC). The PLIC set up by the user, is the device, specialized on the solution of a specific objective, so high–speed. In those areas where fast processing of big data streams is necessary, use even the modern microprocessors is impossible because of their small high–speed performance. In all these cases one of effective options of the hardware implementation is use as element basis the PLIC. The most perspective variety the PLIC are FPGA (Field Programming Gate Array — programmable space of arrays of gates). Popularity the PLIC FPGA around the world continuously increases because of their high high–speed performance, small time before release of a finished article, low complexity of technology of release of ready system, low cost of manufacture of system and small overall dimensions. These aspects also served as the principal reason of the hardware implementation of the generator of a graphic primitive on the basis of aforementioned technology.

Figure 3 — Xilinx Spartan–3E FPGA
Attempt to test the developed algorithm on FPGA was made not only to envelop all areas of its optimization. The desire to reveal the best method of the solution of tasks, similar to an objective, became the transition reason from program and hardware–software implementation of algorithm to especially its hardware optimization. Main goals of a firmware of FPGA according to algorithm of generation of a graphic primitive are loading of initial arbitrary data in FPGA interface means, algorithm testing with the subsequent output of results and the analysis of time response characteristics. The specialized computing kernel which will allow to receive authentic results of generation for minimum possible quantity of the hardware clock periods will be developed for obtaining the maximum productivity of operation of algorithm.
Conclusion
When I wrote my masters research report the research process was not only theoretical procedure. All of the practical results are confirmed from the point of view of softwarecand software–hardware levels of algorithm improvements. The following stages had been passed by algorithm during research process:
- Main task formulation.
- The analysis of the algorithmic framework which became the basis for the developed algorithm.
- Testing of algorithm using CPU, calculation of time delay and occuracy characteristics.
- Optimization of algorithm according to CUDA restrictions and requirements. Testing of algorithm using GPU and CPU, calculation of time delay and occuracy characteristics.
My experience received during research process shows that every idea could be implemented using high spectrum of possibilities. Every idea could pass the way from its creation up to its practical implementation using various platforms and architectures.
During writing this referat, the master’s work is not finished. It will be finished in December 2012. The full version of work will be available after previously named date. For more information contact the author or her master’s leader.
References
- Башков Е.А., Авксентьева О.А., Аль–Орайкат Анас М. К построению генератора графических примитивов для трехмерных дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія «Проблеми моделювання та автоматизації проектування динамічних систем». Вип. 7(150). — Донецьк, ДонНТУ. — 2008 .— ст. 203–214.
- Favalora G.E. Volumetric 3D Displays and Application Infrastructure [Текст] // «Computer», 2005, August, pp 37–44.
- Spartan–3E FPGA Family: Data Sheet [Электронный ресурс]. — Режим доступа: http://www.xilinx.com/support/documentation/data_sheets/ds312.pdf.
- Spartan–3E Starter Kit Board User Guide [Электронный ресурс]. — Режим доступа: http://www.digilentinc.com/Data/Products/S3EBOARD/S3EStarter_ug230.pdf.
- Andres M. Trianon. Volumetric display technology [Электронный ресурс]. — Режим доступа: http://www.ucsi.edu.my/cervie/ijasa/volume2/depth.asp.
- Винсент Бретон. Медицинские изображения и их обработка [Электронный ресурс]. — Режим доступа: http://gridclub.ru/library/publication.2008-02-14.8426200060/publ_file/.
- Шаламов А.В., Мазеин П.Г. Виды кривых и поверхностей, используемых в современных CAD системах [Электронный ресурс]. — Режим доступа: http://scholar.urc.ac.ru/ped_journal/numero5/article5.html.
- Башков Е.А., Авксентьева О.А., Аль–Орайкат Анас М, Дубровина О.Д. Алгоритмический базис построения генераторов отрезков прямых для 3D дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія «Обчислювальна техніка та автоматизація». Вип. 169(18)/ Редкол.: Башков Є.О. (голова) та ін. — Донецьк: ДонНТУ, 2010. — 250 с.
- Башков Е.А., Авксентьева О.А., Харченко Н.О. Метод воксельного разложения произвольной дуги для объемных 3D дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія «Проблеми моделювання та автоматизації проектування». Вип. 9(179), Донецьк: ДонНТУ, 2011. — 18 с.
- Харченко Н.О. Структурно–алгоритмическая организация устройств генерации произвольных дуг и секторов в 3D пространстве для объемных дисплеев [Электронный ресурс]. — Режим доступа: http://masters.donntu.ru/2011/fknt/hartchenko/diss/index.htm.
- Хромова Е.Н. Построение сеточной модели объектов сложной формы по произвольному набору точек для визуализации и моделирования в трехмерном пространстве [Электронный ресурс]. — Режим доступа: http://masters.donntu.ru/2006/fvti/khromova/diss/index.htm.
- Захаров С.С. Компьютерное моделирование природных явлений: визуализация неба и облаков [Электронный ресурс]. — Режим доступа: http://masters.donntu.ru/2005/fvti/zaharov/libraries/work.htm.
- Статья в Wikipedia о CUDA [Электронный ресурс]. — Режим доступа: http://ru.wikipedia.org/wiki/CUDA.
- Nvidia CUDA Programming Guide [Электронный ресурс]. — Режим доступа: http://developer.download.nvidia.com/compute/cuda/3_0/toolkit/docs/NVIDIA_CUDA_ProgrammingGuide.pdf.
- Зубинский Андрей. NVIDIA Cuda: унификация графики и вычислений [Электронный ресурс]. — Режим доступа: http://ko.com.ua/node/27969.
- Antonio Tumeo. Politecnico di Milano. Massively Parallel Computing with CUDA [Электронный ресурс]. — Режим доступа: http://www.ogf.org/OGF25/materials/1605/CUDA_Programming.pdf.
- Nvidia CUDA Development Tools. Getting started [Электронный ресурс]. — Режим доступа: http://www2.engr.arizona.edu/~ece569a/Readings/NVIDIA_Resources/QuickStart%20Guide.pdf.
- Nvidia CUDA Reference Manual [Электронный ресурс]. — Режим доступа: http://developer.download.nvidia.com/compute/cuda/2_3/toolkit/docs/CUDA_Reference_Manual_2.3.pdf.
- dimson3d. Знакомство с NVIDIA CUDA, параллельные вычисления с помощью GPU в CG [Электронный ресурс]. — Режим доступа: http://www.render.ru/books/show_book.php?book_id=840&start=1.
- Nvidia Corporation. CUDA: new architucture for GPU computing [Электронный ресурс]. — Режим доступа: http://www.nvidia.ru/content/cudazone/download/ru/CUDA_for_games.pdf.