
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Огляд досліджень та розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Огляд базового алгоритму генерації відрізка прямої в тривимірному просторі
- 5. Подальша модифікація алгоритму. Застосування технології CUDA
- 6. Реалізація пристрою генератора відрізків прямих на FPGA
- Висновки
- Перелік посилань
Вступ
Основним засобом взаємодії обчислювальної техніки і людини на сьогоднішній день є пристрої відображення інформації, за допомогою яких результати обробки деяких даних комп’ютером надаються користувачеві. Залишаючи осторонь виведення алфавітно–цифрової інформації, більш орієнтованої на підтримку мовної комунікації, відображення даних у вигляді природних або штучних графічних образів стало в даний час найпоширенішим способом надання людині великих обсягів інформації. [1]
Дисплеї, що дозволяють виводити візуальну інформацію в «реальному» тривимірному просторі (3D–дисплеї) представляють одне з найцікавіших напрямів в розвитку технології відображення інформації. В даний час бурхливо розвиваються нові підходи до побудови 3D–дисплеїв. При цьому переслідується основна мета — можливість надати людині (оператору) більший обсяг візуальної інформації в реальному часі, не перевантажуючи його органи почуттів і мозок. Такого роду дисплеї мають широкі перспективи для застосування в системах автоматизованого управління, побудови тренажерів. Сучасна класифікація [2] 3D пристроїв візуалізації об’єктів та зображень виділяє як особливий клас системи, побудовані на базі об’ємних технологій. Такі пристрої використовуються без спеціальних допоміжних аксесуарів для оператора, все обладнання для поділу стереоскопічних пар зображень «природно» вбудовано в дисплей.
Широке поширення подібних дисплеїв вимагає не тільки створення власне пристроїв відображення, але і розробки методів тривимірного розкладання сцен і алгоритмів функціонування його елементів. Особливістю пристроїв відображення на базі об’ємних технологій є наявність об’ємного воксельного запам’ятовуючого пристрою — аналога растрової пам’яті двовимірних пристроїв відображення. При генерації тривимірного зображення в воксельній пам’яті програмними засобами створюється «вокселізована» модель реальних об’єктів, що складається із сукупності тривимірних графічних примітивів: відрізків тривимірних прямих, тривимірних площин, дуг, кіл, сферичних трикутників, еліпсоїдів і т.д. [1]
1. Актуальність теми
В ході постійного збільшення інтересу до візуалізації тривимірних образів в просторі пристроїв відображення інформації відповідно зростає потреба в розробці і створенні методів тривимірного розкладання сцен і алгоритмів функціонування його елементів. На відміну від звичайних (2D) дисплеїв, для яких методи растрового розкладання графічних примітивів розроблені досить добре і пройшли широку апробацію практиків, тривимірне розкладання практично не опрацьовано і вимагає досліджень як в напрямку власне методів розкладання, так і в напрямку оптимізації цих методів з точки зору апаратно–програмної та апаратної їх реалізації. На основі даних алгоритмів в подальшому будуть будуватися більш складні графічні об’єкти, їх композиції, а також буде відбуватися формування складних сцен. Сучасний розвиток науки і техніки дозволяє поряд з розробкою ефективних рішень також використовувати різні інструментарії, а саме паралельний підхід. Тому в даній роботі розглянута і застосована нова і прогресивна технологія розпаралелювання на графічних процесорах.
На даний момент більшість алгоритмів і підходів в комп’ютерній графіці орієнтовані на вирішення проблем, що стосуються візуалізації в просторі звичних пристроїв відображення інформації: моніторів, графобудівники, табло рядка, що біжить, і інших. Більш вузькою сферою є відображення графічних образів і елементів сцен за допомогою об’ємних дисплеїв. Апаратною заміною об’ємного пристрою відображення інформації можуть виступати вже готові програмні продукти, що відображають окрему частину тривимірного безперервного Евклидова простору (MatLab, MathCAD, SciDAVis). Це дозволяє вирішити проблему перевірки результатів розробленого алгоритму за причин недоступності матеріальної бази через її дорожнечу і відсутності в достатній мірі перевірених і надійних апаратних рішень. Особлива увага також приділяється оптимізації роботи алгоритмів тривимірної графіки з точки зору витраченого часу на генерацію сцени, а також з точки зору апаратних витрат, що часто є визначальним фактором вибору стратегії вирішення поставленого завдання.
2. Мета і задачі дослідження та заплановані результати
Метою дослідження є розробка методів розпаралелювання алгоритмів воксельної генерації графічних примітивів для об’ємних 3D пристроїв відображення.
Основні задачі дослідження:
- Розробка методів генерації воксельного подання відрізка прямої в 3D просторі.
- Дослідження методів паралельної генерації на архітектурі CUDA.
- Дослідження методів паралельної генерації на кластері.
- Розробка спеціалізованого пристрою генерації відрізків прямих в 3D просторі на базі технології FPGA.
Об’єкт дослідження: процес тривимірної дискретизації стандартних графічних примітивів комп’ютерної графіки.
Предмет дослідження: методи і апаратно–програмні засоби побудови об’ємних тривимірних графічних дисплеїв.
У рамках магістерської роботи планується отримання актуальних наукових результатів за наступними напрямками:
- Отримання оптимального методу генерації воксельного подання відрізка прямої в 3D просторі.
- Розробка алгоритму генерації відрізка прямої в 3D просторі на багатопотоковому графічному процесорі архітектури CUDA.
- Розробка спеціалізованого пристрою генерації відрізків прямих в 3D просторі на базі технології FPGA.
Для експериментальної оцінки отриманих теоретичних результатів і формування фундаменту подальших досліджень в якості практичних результатів планується реалізація алгоритму генерації відрізків прямих в 3D просторі за наступними напрямками:
- Реалізація програми, що генерує координати всієї безлічі вокселів, що беруть участь в воксельному розкладанні тривимірного відрізка прямої в просторі 3D дисплея. Експерименти і виміри, які полягають в багаторазових запусках програми на виконання, і подальший аналіз отриманих часових показників і характеристик, що вказують на точність воксельного розкладання, проводилися на базі комп’ютера, який має наступні характеристики: Intel(R) Core(TM)2 Duo CPU E4600 2.40GHz, 2.40ГГц, 1,99ГБ ОЗП.
- До програмно–апаратних поліпшень, що вносяться до структури алгоритму, відноситься його тестування на базі архітектури CUDA, що передбачає використання графічного процесора в якості основи для ресурсоємних обчислень. Експерименти, спрямовані на розпаралелювання виконання програми, проводилися на базі комп’ютера, який має наступні характеристики: Intel(R) Core(TM)2 Duo CPU E4600 2.40GHz, 2.40ГГц, 1,99ГБ ОЗП.
- Апаратна реалізація алгоритму буде проводитися на основі FPGA Spartan–3E фірми Xilinx [3–4] шляхом створення спеціалізлваного обчислювального ядра та занурення його на плату. Таким чином, буде здійснена спроба створення спеціалізованого пристрою, спрямованого на вирішення конкретного завдання — воксельного розкладання графічного примітиву.
3. Огляд досліджень та розробок
Тривимірна воксельна графіка є на сьогоднішній момент досить актуальною і цікавою темою, тому дослідження, пов’язані з даною тематикою, не є новинкою. Існує значна кількість статей, в тексті яких автори розкривають різні сфери застосування воксельної графіки, а також розглядають проблеми, що стоять на шляху її впровадження. Ці статті в більшій частині є зарубіжними і носять загальний характер. Однак спеціалізовані розробки, спрямовані саме на генерацію графічних примітивів в просторі тривимірних дисплеїв, є в достатній мірі новою і малодослідженою галуззю знань.
3.1 Огляд міжнародних джерел
Андрес М. Тріанон у своїй статті на тему тривимірних пристроїв відображення розглядає основні типи об’ємних дисплеїв, їх переваги та недоліки, а також шляхи подальшого розвитку. [5]
Застосування воксельної графіки в контексті побудови зображень, які допомагають лікарям поставити пацієнту правильний діагноз, у своїй статті розглядає Вінсент Бретон. [6]
Воксельну графіку в якості додатків до популярних CAD систем, за допомогою яких створюються і моделюються тривимірні моделі тіл, розглядають Шаламов А.В. і Мазеїн П.Г. [7]
3.2 Огляд національних джерел
Башков Є.О., Авксентьєва О.О., Аль–Орайкат Анас Махмуд у своїй статті розглядають способи побудови графічних примітивів у просторі тривимірних дисплеїв. [1]
Є.О.Башков, Аль–Орайкат Анас Махмуд, Дубровіна О.Д., Авксентьєва О.О. в своїй статті розглядають алгоритмічний базис побудови генераторів відрізків прямих для 3D дисплеїв. [8]
Є.О.Башков, Харченко М.О., Авксентьєва О.О. в своїй статті розглядають метод воксельного розкладання довільної дуги для об’ємних 3D дисплеїв. [9]
3.3 Огляд локальних джерел
Магістр Харченко М.О. розглядає проблему воксельного розкладання довільної дуги для об’ємних 3D дисплеїв. [10]
Магістр Хромова Є.Н. розглядає проблему побудови сіткової моделі об’єктів складної форми за довільним набором точок для візуалізації та моделювання в тривимірному просторі. [11]
Магістр Захаров С.С. розглядає проблему комп’ютерного моделювання природних явищ: візуалізації неба і хмар. [12]
4. Огляд базового алгоритму генерації відрізка прямої в тривимірному просторі
Задача растрового розкладання відрізка прямої формулюється як задача визначення безлічі вокселів, що знаходяться в просторі 3D дисплея, до якого належать початковий і кінцевий вокселі генерації, кожен з яких (крім початкового і кінцевого) має два і лише два сусідніх вокселі, центр кожного з яких лежить на мінімальній відстані від прямої і їх кількість в безлічі мінімальна. Суть алгоритму полягає в тому, що на певному кроці генерації є деякий отриманий воксель послідовності, і потрібно визначити наступний воксель растрового розкладання. Для цього розглядаються сім сусідніх вокселів–претендентів в напрямку, який визначається напрямковим вектором відрізка прямої. Обчислюються відстані між їх центрами і заданою прямою. Наступний в послідовності воксель визначається як воксель–претендент з мінімальною відстанню до прямої. Таким чином будується безліч вокселів в растровому розкладанні відрізка прямої.
На базі вищевикладеного алгоритму реалізована програма. Результати роботи програми наведені нижче на рисунку 1. Координати вокселів, отриманих в ході виконання програми, записуються в текстовий файл, що має спеціальну структуру. Після створення такого файлу, що містить координати всіх вокселів, що входять в воксельне розкладання тривимірного відрізка прямої в просторі тривимірного дисплея, його можна обробляти за допомогою будь–якого тривимірного візуалізатора. В якості середовища візуалізації, що моделює частину Евклидова простору, відображуваного тривимірним дисплеєм, був обраний програмний пакет SciDAVis.
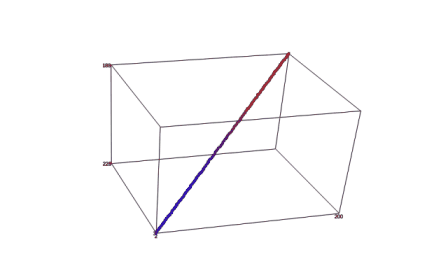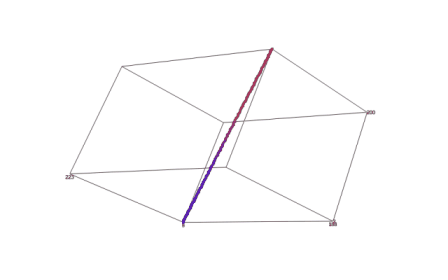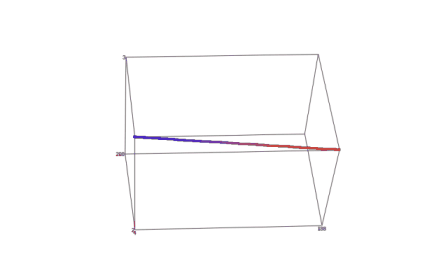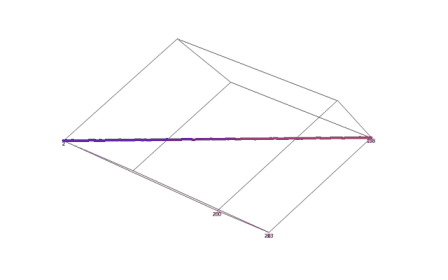
Рисунок 1 — Результат візуалізації воксельного розкладання відрізка прямої, що задається довільними параметрами в просторі тривимірного дисплея (середовище візуалізації — програмний пакет SciDAVis)
15 кадрів. Затримка після кадрів = 250 мсек.
Розмір анімації: 448px х 280px. Розмір файлу: 93.8 Kbytes. Створено за допомогою MP GIF Animator.
5. Подальша модифікація алгоритму. Застосування технології CUDA
«CUDA (англ. Compute Unified Device Architecture) — програмно–апаратна архітектура, що дозволяє виконувати обчислення з використанням графічних процесорів NVIDIA, що підтримують технологію GPGPU (довільних обчислень на відеокартах). Архітектура CUDA вперше з’явилася на ринку з виходом чіпа NVIDIA восьмого покоління — G80 і присутня у всіх наступних серіях графічних чіпів, які використовуються в сімействах прискорювачів GeForce, Quadro і Tesla. CUDA SDK дозволяє програмістам реалізовувати на спеціальному спрощеному діалекті мови програмування Сі алгоритми, здійснимі на графічних процесорах NVIDIA, і включати спеціальні функції в текст програми на Cі. CUDA дає розробнику можливість на свій розсуд організовувати доступ до набору інструкцій графічного прискорювача і управляти його пам’яттю, організовувати на ньому складні паралельні обчислення.» [13]
При використанні GPU розробнику доступно декілька видів пам’яті: регістри, локальна, глобальна, розділяєма, константна і текстурна пам’ять. Кожна з цих типів пам’яті має певне призначення, яке обумовлюється її технічними параметрами (швидкість роботи, рівень доступу на читання і запис) [14]. Ієрархія типів пам’яті наведена на рисунку 2.
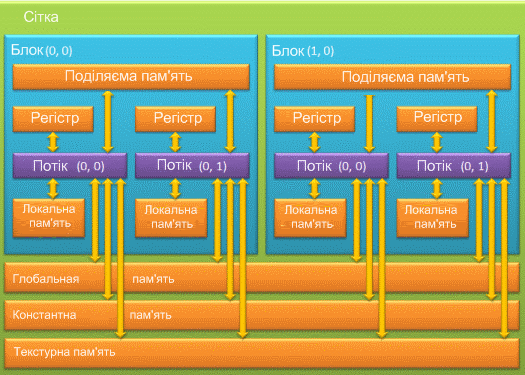
Рисунок 2 — Типи пам’яті відеокарти
Під час програмно–апаратної оптимізації розробленого алгоритму архітектура CUDA використовувалася у якості обчислювального середовища, що дозволяє розпаралелювати деякі частини програми [15]. За рахунок того, що програму на мові Сі можна за нетривалий проміжок часу оптимізувати і реструктурувати відповідно до вимог, що пред’являються CUDA до програм, що виконуються на GPU, алгоритм був інтерпретований на специфічний діалект мови Сі, який має специфічні функції і типи CUDA SDK, які обов’язково необхідні для роботи з архітектурою графічних процесорів NVIDIA [16–18]. Але крім складнощів, що виникли під час перекладу програми, що реалізує алгоритм воксельного розкладання тривимірного відрізка прямої, на шляху подальшої оптимізації стали проблеми пошуку блоків алгоритму, які можна було б піддати паралельній реалізації [19–20]. Такі блоки були знайдені, більшою частиною яких були послідовні цикли. Їх вийшло виконувати одночасно. Дана перевага істотно знижує час роботи програми, так як час виконання програми зворотньопропорційний кількістю повторень циклів в програмі.
Важливою задачею, яку було необхідно вирішити, став пошук методу заміру часу, що витрачається на виконання програми під час пробних циклів запуску. Стандартні методи, підтримувані Microsoft Visual Studio (наприклад, застосування функції GetTickCount на початку програми, а потім в її кінці з подальшим визначенням різниці цих величин) не можуть бути застосовані, тому що на практиці було з’ясовано, що застосування такого заміру дає неправильний результат. Вихід із ситуації був знайдений. Застосування саме стандартних засобів, підтримуваних архітектурою CUDA, стало найбільш зручним і точним методом виміру часу роботи програми. Таким засобом став Compute Visual Profiler. У міру збільшення кількості пробних циклів запуску ступінь розпаралелювання алгоритму програми збільшувалася. В залежності від кількості пробних запусків прискорення, показуване GPU в порівнянні з CPU, склало від чотирьох до восьми разів. Такі результати були цілком передбачувані, тому що ступінь розпаралелювання дорівнювала кількості вокселів–претендентів на входження в воксельне розкладання. Таким чином, підрахунок всіх характеристик, властивих кожному вокселю–претенденту, відбувався паралельно.
6. Реалізація пристрою генератора відрізків прямих на FPGA
Найбільш ефективною елементною базою останніх років вважаються програмовані логічні інтегральні схеми (ПЛІС). Налагоджена користувачем ПЛІС, є пристроєм, спеціалізованим на рішення конкретної задачі, а тому і швидкодіючим. У тих областях, де необхідна швидка обробка великих потоків даних, використання навіть найсучасніших мікропроцесорів неможливе через їх малу швидкодію. У всіх цих випадках одним з ефективних варіантів апаратної реалізації є використання в якості елементної бази ПЛІС. Найбільш перспективним різновидом ПЛІС є FPGA (Field Programming Gate Array — програмований простір масивів вентилів). Популярність ПЛІС FPGA у всьому світі безперервно зростає через їх високі швидкодії, малий час до випуску готового виробу, низьку складність технології випуску готової системи, низьку вартість виготовлення системи і малі габарити. Ці аспекти і послужили головною причиною апаратної реалізації генератора графічного примітиву саме на базі вищезгаданої технології.

Рисунок 3 — FPGA Spartan–3E фірми Xilinx
Спроба протестувати розроблений алгоритм на FPGA була зроблена не тільки для того, щоб охопити всі області його оптимізації. Саме бажання виявити найкращий спосіб вирішення задач, подібних поставленому завданню, стало причиною переходу від програмної та програмно–апаратної реалізації алгоритму до суто апаратної його оптимізації. Головними цілями прошивки FPGA відповідно до алгоритму генерації графічного примітиву є завантаження початкових довільних даних у FPGA за допомогою інтерфейсу, тестування алгоритму з подальшою видачею результатів і аналіз часових характеристик. Для отримання максимальної продуктивності роботи алгоритму буде розроблено спеціалізоване обчислювальнe ядро, яке дозволить отримати достовірні результати генерації за мінімально можливу кількість апаратних тактів.
Висновки
На момент написання магістерської роботи дослідження, проведені в її рамках, носили не тільки теоретичний характер, але й були підтверджені на програмному та програмно–апаратному рівнях. Розроблений в ході виконання магістерської роботи алгоритм пройшов наступні стадії:
- Формулювання задачі.
- Аналіз алгоритмічної основи, що стала базисом для алгоритму, що розробляється.
- Тестування алгоритму, заміри часових характеристик і ознак, що вказують на точність генерації графічного примітиву.
- Модернізація та оптимізація алгоритму відповідно до вимог, що пред’являються до програм з боку платформи CUDA. Перевірка працездатності алгоритму на GPU компанії nVidia з підтримкою технології CUDA. Аналіз отриманих часових характеристик, а також показників, що вказують на точність виконання алгоритму.
Досвід роботи з розробленим алгоритмом на різних рівнях реалізації показав, що будь–яка ідея може бути реалізована різними способами. Кожна ідея може пройти шлях від концепції до конкретного впровадження і практичної реалізації. Алгоритм, на перших стадіях реалізований в якості програми, може пройти стадії багаторазових модифікацій, поліпшень і вдосконалень.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2012 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Перелік посилань
- Башков Е.А., Авксентьева О.А., Аль–Орайкат Анас М. К построению генератора графических примитивов для трехмерных дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія «Проблеми моделювання та автоматизації проектування динамічних систем». Вип. 7(150). — Донецьк, ДонНТУ. — 2008 .— ст. 203–214.
- Favalora G.E. Volumetric 3D Displays and Application Infrastructure [Текст] // «Computer», 2005, August, pp 37–44.
- Spartan–3E FPGA Family: Data Sheet [Электронный ресурс]. — Режим доступа: http://www.xilinx.com/support/documentation/data_sheets/ds312.pdf.
- Spartan–3E Starter Kit Board User Guide [Электронный ресурс]. — Режим доступа: http://www.digilentinc.com/Data/Products/S3EBOARD/S3EStarter_ug230.pdf.
- Andres M. Trianon. Volumetric display technology [Электронный ресурс]. — Режим доступа: http://www.ucsi.edu.my/cervie/ijasa/volume2/depth.asp.
- Винсент Бретон. Медицинские изображения и их обработка [Электронный ресурс]. — Режим доступа: http://gridclub.ru/library/publication.2008-02-14.8426200060/publ_file/.
- Шаламов А.В., Мазеин П.Г. Виды кривых и поверхностей, используемых в современных CAD системах [Электронный ресурс]. — Режим доступа: http://scholar.urc.ac.ru/ped_journal/numero5/article5.html.
- Башков Е.А., Авксентьева О.А., Аль–Орайкат Анас М, Дубровина О.Д. Алгоритмический базис построения генераторов отрезков прямых для 3D дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія «Обчислювальна техніка та автоматизація». Вип. 169(18)/ Редкол.: Башков Є.О. (голова) та ін. — Донецьк: ДонНТУ, 2010. — 250 с.
- Башков Е.А., Авксентьева О.А., Харченко Н.О. Метод воксельного разложения произвольной дуги для объемных 3D дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія «Проблеми моделювання та автоматизації проектування». Вип. 9(179), Донецьк: ДонНТУ, 2011. — 18 с.
- Харченко Н.О. Структурно–алгоритмическая организация устройств генерации произвольных дуг и секторов в 3D пространстве для объемных дисплеев [Электронный ресурс]. — Режим доступа: http://masters.donntu.ru/2011/fknt/hartchenko/diss/index.htm.
- Хромова Е.Н. Построение сеточной модели объектов сложной формы по произвольному набору точек для визуализации и моделирования в трехмерном пространстве [Электронный ресурс]. — Режим доступа: http://masters.donntu.ru/2006/fvti/khromova/diss/index.htm.
- Захаров С.С. Компьютерное моделирование природных явлений: визуализация неба и облаков [Электронный ресурс]. — Режим доступа: http://masters.donntu.ru/2005/fvti/zaharov/libraries/work.htm.
- Статья в Wikipedia о CUDA [Электронный ресурс]. — Режим доступа: http://ru.wikipedia.org/wiki/CUDA.
- Nvidia CUDA Programming Guide [Электронный ресурс]. — Режим доступа: http://developer.download.nvidia.com/compute/cuda/3_0/toolkit/docs/NVIDIA_CUDA_ProgrammingGuide.pdf.
- Зубинский Андрей. NVIDIA Cuda: унификация графики и вычислений [Электронный ресурс]. — Режим доступа: http://ko.com.ua/node/27969.
- Antonio Tumeo. Politecnico di Milano. Massively Parallel Computing with CUDA [Электронный ресурс]. — Режим доступа: http://www.ogf.org/OGF25/materials/1605/CUDA_Programming.pdf.
- Nvidia CUDA Development Tools. Getting started [Электронный ресурс]. — Режим доступа: http://www2.engr.arizona.edu/~ece569a/Readings/NVIDIA_Resources/QuickStart%20Guide.pdf.
- Nvidia CUDA Reference Manual [Электронный ресурс]. — Режим доступа: http://developer.download.nvidia.com/compute/cuda/2_3/toolkit/docs/CUDA_Reference_Manual_2.3.pdf.
- dimson3d. Знакомство с NVIDIA CUDA, параллельные вычисления с помощью GPU в CG [Электронный ресурс]. — Режим доступа: http://www.render.ru/books/show_book.php?book_id=840&start=1.
- Nvidia Corporation. CUDA: new architucture for GPU computing [Электронный ресурс]. — Режим доступа: http://www.nvidia.ru/content/cudazone/download/ru/CUDA_for_games.pdf.