
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Обзор базового алгоритма генерации отрезка прямой в трехмерном пространстве
- 5. Дальнейшая модификация алгоритма. Применение технологии CUDA
- 6. Реализация устройства генератора отрезков прямых на FPGA
- Выводы
- Список источников
Введение
Основным средством взаимодействия вычислительной техники и человека на сегодняшний день являются устройства отображения информации, посредством которых результаты обработки некоторых данных компьютером предоставляются пользователю. Оставляя в стороне вывод алфавитно–цифровой информации, более ориентированной на поддержку языковой коммуникации, отображение данных в виде естественных или искусственных графических образов стало в настоящее время самым распространенным способом доведения человеку больших объемов информации. [1]
Дисплеи, позволяющие выводить визуальную информацию в «реальном» трехмерном пространстве (3D–дисплеи) представляют одно из самых интересных направлений в развитии технологии отображения информации. В настоящее время бурно развиваются новые подходы к построению 3D–дисплеев. При этом преследуется основная цель — возможность предоставить человеку (оператору) больший объем визуальной информации в реальном времени, не перегружая его органы чувств и мозг. Такого рода дисплеи имеют широкие перспективы для применения в системах автоматизированного управления, построения тренажеров. Современная классификация [2] 3D устройств визуализации объектов и изображений выделяет как особый класс системы, построенные на базе объемных технологий. Такие устройства подразумевают отсутствие специальных вспомогательных аксессуаров для оператора, все оборудование для разделения стереоскопических пар изображений «естественно» встроено в дисплей.
Широкое распространение подобных дисплеев требует не только создания собственно отображающих устройств, но и разработки методов трехмерного разложения сцен и алгоритмов функционирования его элементов. Особенностью устройств отображения на базе объемных технологий является наличие объемного воксельного запоминающего устройства — аналога растровой памяти двумерных устройств отображения. При генерации трехмерного изображения в воксельной памяти программными средствами создается «вокселизированная» модель реальных объектов, состоящая из совокупности трехмерных графических примитивов: отрезков трехмерных прямых, трехмерных плоскостей, дуг, окружностей, сферических треугольников, эллипсоидов и т.п. [1]
1. Актуальность темы
В ходе постоянного увеличения интереса к визуализации трехмерных образов в пространстве устройств отображения информации соответственно возрастает потребность в разработке и создании методов трехмерного разложения сцен и алгоритмов функционирования его элементов. В отличие от обычных (2D) дисплеев, для которых методы растрового разложения графических примитивов разработаны достаточно хорошо и прошли широкую апробацию практиков, трехмерное разложение практически не проработано и требует исследований как в направлении собственно методов разложения, так и в направлении оптимизации этих методов с точки зрения аппаратно–программной и аппаратной их реализации. На основе данных алгоритмов в последующем будут строиться более сложные графические объекты, их композиции, а также будет происходить формирование сложных сцен. Современное развитие науки и техники позволяет наряду с разработкой эффективных решений также использовать различные инструментарии, а именно параллельный подход. Поэтому в данной работе рассмотрена и применена новая и прогрессивная технология распараллеливания на графических процессорах.
На данный момент большинство алгоритмов и подходов в компьютерной графике ориентированы на разрешение проблем, касающихся визуализации в пространстве привычных устройств отображения информации: мониторов, графопостроителей, табло бегущей строки и прочих. Более узкой сферой является отображение графических образов и элементов сцен при помощи объемных дисплеев. Аппаратной заменой объемного устройства отображения информации могут выступать уже готовые программные продукты, отображающие отдельную часть трехмерного непрерывного Евклидова пространства (MatLab, MathCAD, SciDAVis). Это позволяет решить проблему проверки результатов разработанного алгоритма в виду недоступности материальной базы из–за ее дороговизны и отсутствия в достаточной мере проверенных и надёжных аппаратных решений. Особое внимание также уделяется оптимизации работы алгоритмов трехмерной графики с точки зрения затраченного времени на генерацию сцены, а также с точки зрения аппаратных затрат, что зачастую является определяющим фактором выбора стратегии решения поставленной задачи.
2. Цель и задачи исследования, планируемые результаты
Целью исследования является разработка методов распараллеливания алгоритмов воксельного представления графических примитивов для объемных 3D устройств отображения.
Основные задачи исследования:
- Разработка методов генерации воксельного представления отрезка прямой в 3D пространстве.
- Исследование методов параллельной генерации на архитектуре CUDA.
- Исследование методов параллельной генерации на кластере.
- Разработка специализированного устройства генерации отрезков прямых в 3D пространстве на базе технологии FPGA.
Объект исследования: процесс трехмерной дискретизации стандартных графических примитивов компьютерной графики.
Предмет исследования: методы и аппаратно–программные средства построения объемных трехмерных графических дисплеев.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- Получение оптимального метода генерации воксельного представления отрезка прямой в 3D пространстве.
- Разработка алгоритма генерации отрезка прямой в 3D пространстве на многопотоковом графическом процессоре архитектуры CUDA.
- Разработка специализированного устройства генерации отрезков прямых в 3D пространстве на базе технологии FPGA.
Для экспериментальной оценки полученных теоретических результатов и формирования фундамента последующих исследований в качестве практических результатов планируется реализация алгоритма генерации отрезков прямых в 3D пространстве в следующих направлениях:
- Реализация программы, генерирующая координаты всего множества вокселей, участвующих в воксельном разложении трехмерного отрезка прямой в пространстве 3D дисплея. Эксперименты и замеры, заключающиеся в многократных запусках программы на выполнение, и дальнейший анализ полученных временных показателей и характеристик, указывающих на точность воксельного разложения, проводились на базе компьютера, обладающего следующими характеристиками: Intel(R) Core(TM)2 Duo CPU E4600 2.40GHz, 2.40ГГц, 1,99ГБ ОЗУ.
- К программно–аппаратным улучшениям, вносимым в структуру алгоритма, относится его тестирование на базе архитектуры CUDA, что подразумевает использование графического процессора в качестве основы для ресурсоёмких вычислений. Эксперименты, направленные на распараллеливание выполнения программы, проводились на базе компьютера, обладающего следующими характеристиками: Intel(R) Core(TM)2 Duo CPU E4600 2.40GHz, 2.40ГГц, 1,99ГБ ОЗУ.
- Аппаратная реализация алгоритма будет производиться на основе FPGA Spartan–3E фирмы Xilinx [3–4] путем создания специализированного вычислительного ядра и погружения его на плату. Таким образом, будет совершена попытка создания специализированного устройства, направленного на решение конкретной задачи — воксельного разложения графического примитива.
3. Обзор исследований и разработок
Трехмерная воксельная графика является на сегодняшний момент довольно актуальной и интересной темой, поэтому исследования, связанные с данной тематикой, не являются новинкой. Существует значительное количество статей, в тексте которых авторы раскрывают различные области применения воксельной графики, а также рассматривают проблемы, стоящие на пути ее внедрения. Эти статьи в большей части являются зарубежными и носят общий характер. Однако специализированные разработки, направленные именно на генерацию графических примитивов в пространстве трехмерных дисплеев, являются в достаточной мере новой и малоисследованной областью знаний.
3.1 Обзор международных источников
Андрес М. Трианон в своей статье на тему трехмерных устройств отображения рассматривает основные типы объемных дисплеев, их преимущества и недостатки, а также пути дальнейшего развития. [5]
Применение воксельной графики в контексте построения изображений, помогающих врачам поставить пациенту правильный диагноз, в своей статье рассматривает Винсент Бретон. [6]
Воксельную графику в качестве приложения к популярным CAD системам, с помощью которых создаются и моделируются трехмерные модели тел, рассматривают Шаламов А.В. и Мазеин П.Г. [7]
3.2 Обзор национальных источников
Башков Е.А., Авксентьева О.А., Аль–Орайкат Анас Махмуд в своей статье рассматривают способы построения графических примитивов в пространстве трехмерных дисплеев. [1]
Е.А.Башков, Аль–Орайкат Анас Махмуд, Дубровина О.Д., Авксентьева О.А. в своей статье рассматривают алгоритмический базис построения генераторов отрезков прямых для 3D дисплеев. [8]
Е.А.Башков, Харченко Н.О., Авксентьева О.А. в своей статье рассматривают метод воксельного разложения произвольной дуги для объемных 3D дисплеев. [9]
3.3 Обзор локальных источников
Магистр Харченко Н.О. рассматривает проблему воксельного разложения произвольной дуги для объемных 3D дисплеев. [10]
Магистр Хромова Е.Н. рассматривает проблему построения сеточной модели объектов сложной формы по произвольному набору точек для визуализации и моделирования в трехмерном пространстве. [11]
Магистр Захаров С.С. рассматривает проблему компьютерного моделирование природных явлений: визуализации неба и облаков. [12]
4. Обзор базового алгоритма генерации отрезка прямой в трехмерном пространстве
Задача растрового разложения отрезка прямой формулируется как задача определения множества вокселей, находящихся в пространстве 3D дисплея, к которому принадлежат начальный и конечный воксели генерации, каждый из которых (кроме начального и конечного) имеет два и только два соседних вокселя, центр каждого из которых лежит на минимальном расстоянии от прямой и их количество во множестве минимально. Суть алгоритма заключается в том, что на определенном шаге генерации имеется некоторый полученный воксель последовательности, и требуется определить следующий воксель растрового разложения. Для этого рассматриваются семь соседних вокселей–претендентов в направлении, которое определяется направляющим вектором отрезка прямой. Вычисляются расстояния между их центрами и заданной прямой. Следующий в последовательности воксель определяется как воксель–претендент с минимальным расстоянием до прямой. Таким способом генерируется множество вокселей в растровом разложении отрезка прямой.
На базе вышеизложенного алгоритма реализована программа. Результаты работы программы приведены ниже на рисунке 1. Координаты вокселей, полученные в ходе выполнения программы, записываются в текстовый файл, обладающий специальной структурой. После построения такого файла, содержащего координаты всех вокселей, входящих в воксельное разложение трехмерного отрезка прямой в пространстве трехмерного дисплея, его можно обрабатывать с помощью любого трехмерного визуализатора. В качестве среды визуализации, моделирующей часть Евклидова пространства, отображаемого трехмерным дисплеем, был выбран программный пакет SciDAVis.
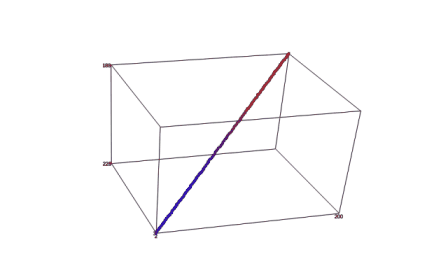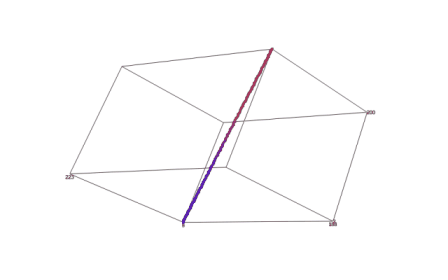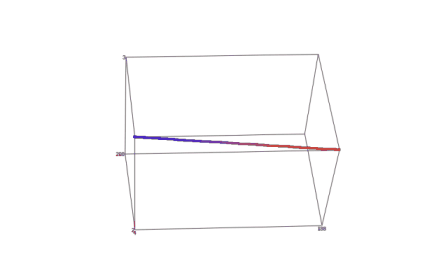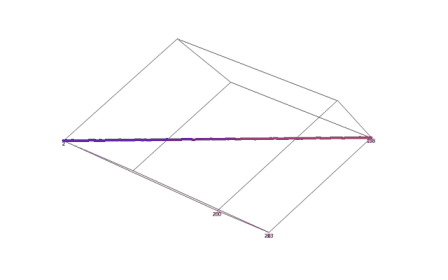
Рисунок 1 — Результат визуализации воксельного разложения отрезка прямой, заданной произвольными параметрами в пространстве трехмерного дисплея (среда визуализации — программный пакет SciDAVis)
15 кадров. Задержка после кадров = 250 мсек.
Размер анимации: 448px х 280px. Размер файла: 93.8 Kbytes. Создано при помощи MP GIF Animator.
5. Дальнейшая модификация алгоритма. Применение технологии CUDA
«CUDA (англ. Compute Unified Device Architecture) — программно–аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU (произвольных вычислений на видеокартах). Архитектура CUDA впервые появились на рынке с выходом чипа NVIDIA восьмого поколения — G80 и присутствует во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, Quadro и Tesla. CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполняемые на графических процессорах NVIDIA, и включать специальные функции в текст программы на Cи. CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью, организовывать на нём сложные параллельные вычисления.» [13]
При использовании GPU разработчику доступно несколько видов памяти: регистры, локальная, глобальная, разделяемая, константная и текстурная память. Каждая из этих типов памяти имеет определенное назначение, которое обуславливается её техническими параметрами (скорость работы, уровень доступа на чтение и запись) [14]. Иерархия типов памяти представлена на рисунке 2.
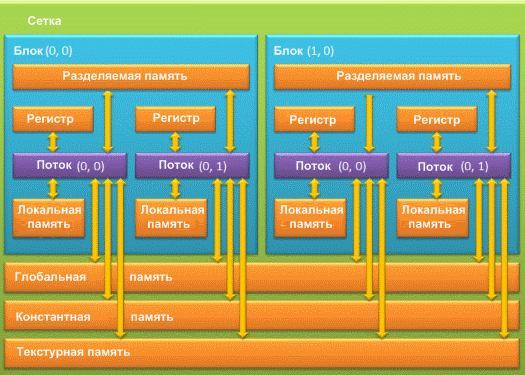
Рисунок 2 — Типы памяти видеокарты
Во время программно–аппаратной оптимизации разработанного алгоритма архитектура CUDA использовалась в качестве вычислительной среды, позволяющей распараллеливать некоторые части программы [15]. За счет того, что программу на языке Си можно за непродолжительный промежуток времени оптимизировать и реструктурировать в соответствии с требованиями, предъявляемыми CUDA к программам, выполняемым на GPU, алгоритм был интерпретирован на специфический диалект языка Си, который имеет специфические функции и типы CUDA SDK, которые обязательно необходимы для работы с архитектурой графических процессоров NVIDIA [16–18]. Но помимо сложностей, возникших во время перевода программы, реализующей алгоритм воксельного разложения трехмерного отрезка прямой, на пути дальнейшей оптимизации стали проблемы поиска блоков алгоритма, которые можно было подвергнуть параллельной реализации [19–20]. Такие блоки были найдены, большей частью которых являлись последовательные циклы. Их получилось выполнять одновременно во времени. Данное преимущество существенно снижает время работы программы, так как время выполнения программы обратнопропорционально количеству повторений циклов в программе.
Важной задачей, которую было необходимо решить, стал поиск метода замера времени, затрачиваемого на выполнение программы во время пробных циклов запуска. Стандартные методы, поддерживаемые Microsoft Visual Studio (например, применение функции GetTickCount() в начале программы, а затем в ее конце с последующим нахождением разности этих величин) не могут быть применены, так как на практике было выяснено, что применение такого замера даёт неправильный результат. Выход из сложившейся ситуации был найден. Применение именно стандартных средств, поддерживаемых архитектурой CUDA, стало наиболее удобным и точным методом замера времени работы программы. Таким средством стал Compute Visual Profiler. По мере увеличения количества пробных циклов запуска степень распараллеливания алгоритма программы увеличивалась. В зависимости от количества пробных запусков ускорение, показываемое GPU по сравнению с CPU, составило от четырех до восьми раз. Такие результаты были вполне предсказуемы, так как степень распараллеливания была равна количеству вокселей-претендентов на вхождение в воксельное разложение. Таким образом, подсчет всех характеристик, присущих каждому вокселю–претенденту, происходил параллельно.
6. Реализация устройства генератора отрезков прямых на FPGA
Наиболее эффективной элементной базой последних лет считаются программируемые логические интегральные схемы (ПЛИС). Настроенная пользователем ПЛИС, является устройством, специализированным на решение конкретной задачи, а значит быстродействующим. В тех областях, где необходима быстрая обработка больших потоков данных, использование даже самых современных микропроцессоров невозможно из–за их малого быстродействия. Во всех этих случаях одним из эффективных вариантов аппаратной реализации является использование в качестве элементной базы ПЛИС. Наиболее перспективной разновидностью ПЛИС являются FPGA (Field Programming Gate Array — программируемое пространство массивов вентилей). Популярность ПЛИС FPGA во всем мире непрерывно возрастает из–за их высокого быстродействия, малого времени до выпуска готового изделия, низкой сложности технологии выпуска готовой системы, низкой стоимости изготовления системы и малых габаритов. Эти аспекты и послужили главной причиной аппаратной реализации генератора графического примитива именно на базе вышеупомянутой технологии.

Рисунок 3 — FPGA Spartan–3E фирмы Xilinx
Попытка протестировать разработанный алгоритм на FPGA была сделана не только для того, чтобы охватить все области его оптимизации. Именно желание выявить наилучший способ решения задач, подобных поставленной задаче, стало причиной перехода от программной и программно–аппаратной реализации алгоритма к сугубо аппаратной его оптимизации. Главными целями прошивки FPGA в соответствии с алгоритмом генерации графического примитива являются загрузка начальных произвольных данных в FPGA посредствами интерфейса, тестирование алгоритма с последующей выдачей результатов и анализ временных характеристик. Для получения максимальной производительности работы алгоритма будет разработано специализированное вычислительное ядро, которое позволит получить достоверные результаты генерации за минимально возможное количество аппаратных тактов.
Выводы
На момент написания магистерской работы исследования, проводимые в ее рамках, носили не только теоретический характер, но и были подтверждены на программном и программно–аппаратном уровнях. Разработанный в ходе выполнения магистерской работы алгоритм прошел следующие стадии:
- Формулировка задачи.
- Анализ алгоритмической основы, ставшей базисом для разрабатываемого алгоритма.
- Тестирование алгоритма, замеры временных характеристик и признаков, указывающих на точность генерации графического примитива.
- Модернизация и оптимизация алгоритма в соответствии с требованиями, предъявляемыми к программам со стороны платформы CUDA. Проверка работоспособности алгоритма на GPU компании nVidia с поддержкой технологии CUDA. Анализ полученных временных характеристик, а также показателей, указывающих на точность выполнения алгоритма.
Опыт работы с разработанным алгоритмом на различных уровнях реализации показал, что любая идея может быть реализована различными способами. Каждая идея может пройти путь от концепции до конкретного внедрения и практической реализации. Алгоритм, на первых порах реализованный в качестве программы, может пройти стадии многократных модификаций, улучшений и усовершенствований.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2012 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Башков Е.А., Авксентьева О.А., Аль–Орайкат Анас М. К построению генератора графических примитивов для трехмерных дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія «Проблеми моделювання та автоматизації проектування динамічних систем». Вип. 7(150). — Донецьк, ДонНТУ. — 2008 .— ст. 203–214.
- Favalora G.E. Volumetric 3D Displays and Application Infrastructure [Текст] // «Computer», 2005, August, pp 37–44.
- Spartan–3E FPGA Family: Data Sheet [Электронный ресурс]. — Режим доступа: http://www.xilinx.com/support/documentation/data_sheets/ds312.pdf.
- Spartan–3E Starter Kit Board User Guide [Электронный ресурс]. — Режим доступа: http://www.digilentinc.com/Data/Products/S3EBOARD/S3EStarter_ug230.pdf.
- Andres M. Trianon. Volumetric display technology [Электронный ресурс]. — Режим доступа: http://www.ucsi.edu.my/cervie/ijasa/volume2/depth.asp.
- Винсент Бретон. Медицинские изображения и их обработка [Электронный ресурс]. — Режим доступа: http://gridclub.ru/library/publication.2008-02-14.8426200060/publ_file/.
- Шаламов А.В., Мазеин П.Г. Виды кривых и поверхностей, используемых в современных CAD системах [Электронный ресурс]. — Режим доступа: http://scholar.urc.ac.ru/ped_journal/numero5/article5.html.
- Башков Е.А., Авксентьева О.А., Аль–Орайкат Анас М, Дубровина О.Д. Алгоритмический базис построения генераторов отрезков прямых для 3D дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія «Обчислювальна техніка та автоматизація». Вип. 169(18)/ Редкол.: Башков Є.О. (голова) та ін. — Донецьк: ДонНТУ, 2010. — 250 с.
- Башков Е.А., Авксентьева О.А., Харченко Н.О. Метод воксельного разложения произвольной дуги для объемных 3D дисплеев [Текст]. В сб. Наукові праці Донецького національного технічного університету, серія «Проблеми моделювання та автоматизації проектування». Вип. 9(179), Донецьк: ДонНТУ, 2011. — 18 с.
- Харченко Н.О. Структурно–алгоритмическая организация устройств генерации произвольных дуг и секторов в 3D пространстве для объемных дисплеев [Электронный ресурс]. — Режим доступа: http://masters.donntu.ru/2011/fknt/hartchenko/diss/index.htm.
- Хромова Е.Н. Построение сеточной модели объектов сложной формы по произвольному набору точек для визуализации и моделирования в трехмерном пространстве [Электронный ресурс]. — Режим доступа: http://masters.donntu.ru/2006/fvti/khromova/diss/index.htm.
- Захаров С.С. Компьютерное моделирование природных явлений: визуализация неба и облаков [Электронный ресурс]. — Режим доступа: http://masters.donntu.ru/2005/fvti/zaharov/libraries/work.htm.
- Статья в Wikipedia о CUDA [Электронный ресурс]. — Режим доступа: http://ru.wikipedia.org/wiki/CUDA.
- Nvidia CUDA Programming Guide [Электронный ресурс]. — Режим доступа: http://developer.download.nvidia.com/compute/cuda/3_0/toolkit/docs/NVIDIA_CUDA_ProgrammingGuide.pdf.
- Зубинский Андрей. NVIDIA Cuda: унификация графики и вычислений [Электронный ресурс]. — Режим доступа: http://ko.com.ua/node/27969.
- Antonio Tumeo. Politecnico di Milano. Massively Parallel Computing with CUDA [Электронный ресурс]. — Режим доступа: http://www.ogf.org/OGF25/materials/1605/CUDA_Programming.pdf.
- Nvidia CUDA Development Tools. Getting started [Электронный ресурс]. — Режим доступа: http://www2.engr.arizona.edu/~ece569a/Readings/NVIDIA_Resources/QuickStart%20Guide.pdf.
- Nvidia CUDA Reference Manual [Электронный ресурс]. — Режим доступа: http://developer.download.nvidia.com/compute/cuda/2_3/toolkit/docs/CUDA_Reference_Manual_2.3.pdf.
- dimson3d. Знакомство с NVIDIA CUDA, параллельные вычисления с помощью GPU в CG [Электронный ресурс]. — Режим доступа: http://www.render.ru/books/show_book.php?book_id=840&start=1.
- Nvidia Corporation. CUDA: new architucture for GPU computing [Электронный ресурс]. — Режим доступа: http://www.nvidia.ru/content/cudazone/download/ru/CUDA_for_games.pdf.