
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1. Обзор международных источников
- 3.2. Обзор локальных источников
- 4. Использование алгоритма А* в вычислении пути
- 5. Параллельная реализация алгоритма А* на CPU
- 6. Использование графического процессора для исследования оптимизации прогнозирования поведения
- Выводы
- Список источников
Введение
Сегодня информационные технологии позволяют активно проводить новые открытия, требующие больших вычислительных мощностей. Моделирование в открытиях играет большую роль. Одним из его важных аспектов является предсказание поведения объекта. Для этого используется множество факторов, такие как вероятность определенного действия объекта, возможность выполнения какого-либо действия, а также характеристики действий и самого объекта.
Сейчас происходит активная интеграция инновационных технологий во многие сферы человеческой деятельности. Значительно возросла роль средств передвижения, постоянно совершенствуются инженерная техника и средства доставки. Однако на практике маршрут далек от оптимального, что приводит к дополнительным затратам времени и топлива.
1. Актуальность
Подвижный объект при различных действиях и обстоятельствах может двигаться по совершенно разным маршрутам. Современные компьютерные технологии предоставляют инструменты для эффективного решения проблемы оптимизации траектории движения. Прогнозирование поведения даёт возможность предсказывать дальнейшие действия и соответствующим образом корректировать линию поведения (маршрут движения). Это позволит получить значительный выигрыш по времени и, как следствие, затратам топлива, а также уменьшит износ техники и позволит смягчить влияние человеческого фактора.
Подобные вычисления являются крайне ресурсоёмкими. Использование оптимальных алгоритмов, а также использование распределенных систем позволяет снизить нагрузку и ускорить процесс вычисления. В связи с этим вопрос об оптимальной реализации прогнозирования поведения является крайне актуальным.
2. Цели и задачи исследования
Целью работы является исследовательский анализ прогнозирования траектории движения подвижного объекта распределенного симулятора тяжелой инженерной техники на графических процессорах при помощи CUDA, а также получение сравнительной характеристики выполнения прогнозирования на CPU и GPU.
3. Обзор исследований и разработок
Скорость вычисления траектории движения является важным параметром при прогнозировании поведения. Однако на сегодня разработаны различные методы ускорения этого процесса.
3.1. Обзор международных источников
Поскольку вычисление траектории используется сразу в нескольких областях (например, игры), более реалистичному расчету пути посвящены статьи Marco Pinter [1] и Amit Patel [2]. Также была проведена конференция Vehicle and Automotive Engineering, где опубликована статья Akos Cservenak и Tamas Szabo [3].
Много внимания уделено и оптимизации вычислений. Существуют работы, посвященные ускорению поиска пути при помощи графических процессоров [4], [5]. Опубликована статья, в которой авторы распараллеливают предсказание воздушного маршрута [6].
Также компания NVIDIA поддерживает собственный ресурс, посвященный разработчикам GPU [7].
3.2. Обзор локальных источников
В Донецком национальном техническом университете вопросами прогнозирования поведения занимались Кривошеев Сергей Васильевич, Аноприенко Александр Яковлевич [8], [9], [10].
Моделирование движения транспортных средств рассмотрены под руководством научных руководителей в работах магистров: Кондратенко А. В. [11], Гапечкина А. И. [12], Паршина А. Н. [13], Порицкого А. В. [14], Водолазского Д. С. [15] и Варича М. В. [16].
4. Использование алгоритма А* в вычислении пути
Существует множество способов описания схемы поведения, однако наиболее рациональным для траектории движения является описание при помощи графов. В теории графов существуют различные методы, предназначенные для решения задачи поиска кратчайшего пути на графе. Поскольку граф не содержит рёбер с отрицательным весом, так как путь не может быть отрицательным – нет убыточных движений [17], оптимальным решением является использование алгоритма Дейкстры. Данный алгоритм находит кратчайшее расстояние от одной из вершин графа до всех остальных.
Для ускорения вычислений используется алгоритм А*, который представляет собой эвристический подход к алгоритму Дейкстры. Задача алгоритма поиска А* состоит в том, что некий подвижный объект должен перейти из точки А в точку B по оптимальной траектории. Участок перемещения объекта содержит различные препятствия, которые необходимо обойти. Кроме этого, возможно добавление различных критериев (минимальный / максимальный угол поворота, ускорение / замедление и т.п.) для перемещения по прогнозируемой траектории.
Для решения этой задачи поле с максимально допустимой детализацией представляется в виде мультиграфа. При этом расстояние является весом ребра. Объект может ходить по горизонтали и вертикали, например, со стоимостью пути 10. Также возможно перемещение по диагонали, стоимость которого является 14 (корень из 102 + 102). Такое поле представлено на рисунке 1. С повышением уровня дискретизации поля увеличивается и точность результата.
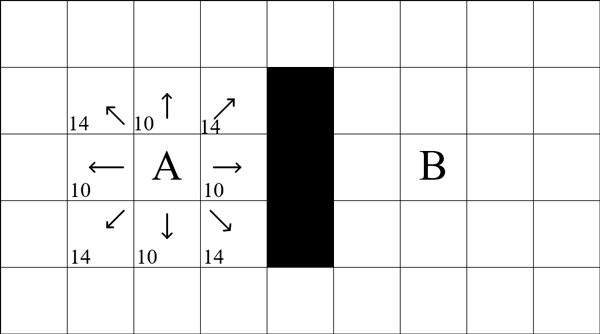
Рисунок 1 – Поле перемещения объекта
В алгоритме А* пошагово просматриваются все пути, ведущие из вершины A в вершину B, пока не найдется путь с минимальной стоимостью.
Алгоритм реализуется следующими шагами:
- Формируются 2 списка вершин: уже рассмотренные вершины и ожидающие рассмотрения. В список рассмотренных заносится A.
- Для каждой вершины высчитывается стоимость пути:
F = G + H, (1)
где: G – стоимость передвижения к текущей вершине из начальной;H – эвристическая стоимость передвижения от текущей вершины до конечной.
- Выбирается вершина с наименьшим F. Если она является B, то сохраняется путь, двигаясь от B назад к целевой точке. Иначе эта вершина выбирается текущей, удаляется из открытого списка и заносится в закрытый.
- Для каждой из точек, соседних с текущей, производятся следующие действия:
- Если соседняя точка уже рассмотрена, то она пропускается.
- если соседней точки нет в списке ожидающих рассмотрения, то она добавляется в этот список. Текущая клетка для неё становится родительской. Рассчитываются F, G, H.
- Если соседняя клетка уже в списке ожидающих рассмотрения, то проверяется, не дешевле ли путь через эту клетку. Стоимость сравнивается по G. Если стоимость меньше, то родитель клетки меняется на текущую клетку и для неё пересчитываются стоимости G и F.
- Если список ожидающих рассмотрения пуст, а цели нет, то это означает, что маршрута до цели не существует.
Таким образом, алгоритм А* не только проведет движущийся объект беспрепятственно к цели, но и при этом обходит минимальное количество вершин, поскольку он эффективно использует эвристику [18]. Пример полного пути, рассчитанного по алгоритму А*, показан на рисунке 2.
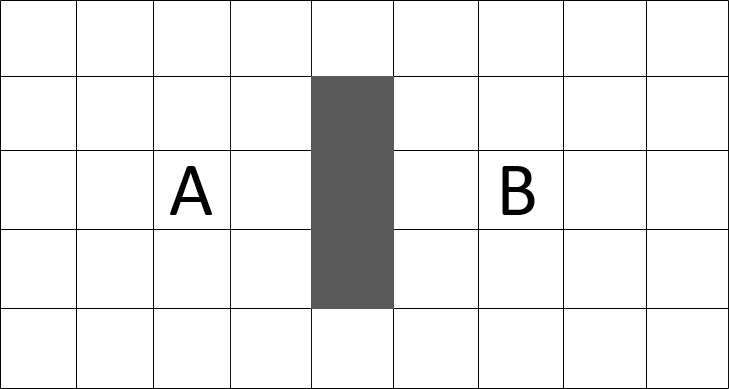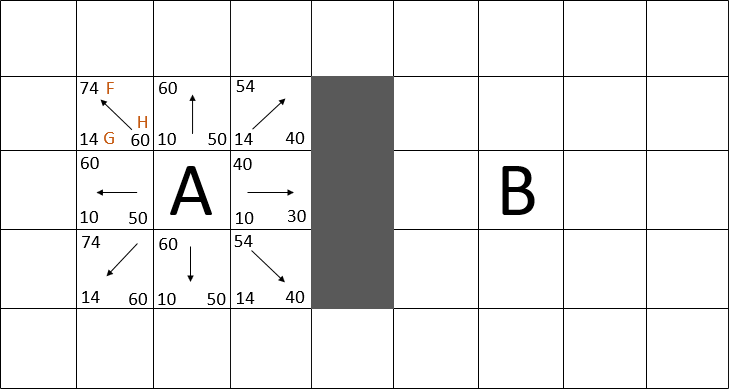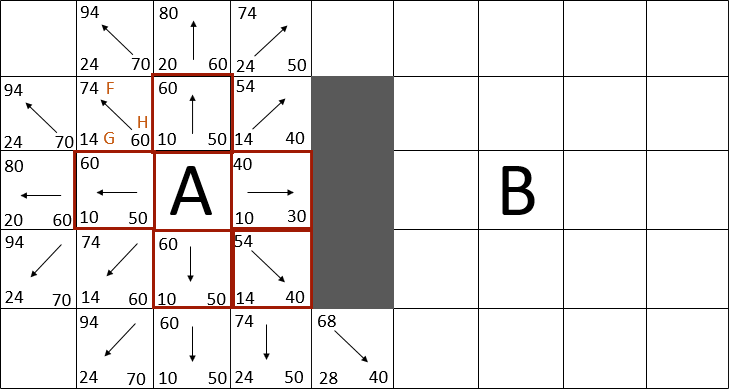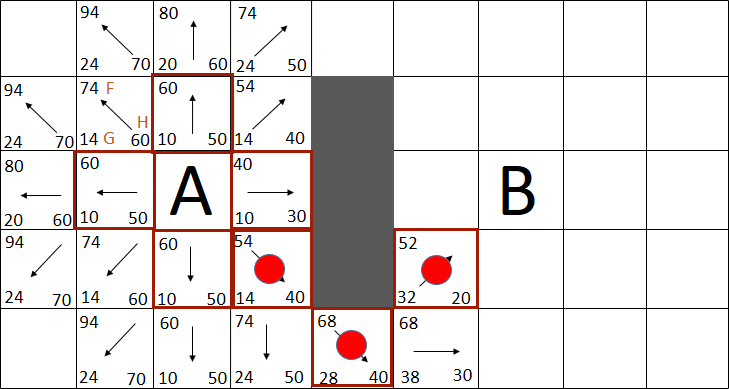
Рисунок 2 – Полный просчет пути от точки A до пункта назначения B (анимация: 8 кадров, 10 повторений, 92 кБ)
5. Параллельная реализация алгоритма А* на CPU
Из анимации видно, что алгоритм вынужден многократно производить последовательный обход 8 соседних вершин для каждой текущей позиции. Такие вычисления являются крайне ресурсоёмкими и по мере увеличения нагрузки, связанной с неудобным позиционированием маршрутных точек и препятствий, сильно возрастает время выполнения программы. Существенного повышения производительности можно добиться путем многопоточной реализации программы.
Многопоточный процесс имеет более сложную организацию, чем однопоточный. Он содержит несколько параллельных потоков, для каждого из которых создается свой стек и присутствуют собственные значения регистров [19]. Преимущества такого подхода:
– повышение производительности программы;
– экономия памяти;
– эффективное использование многоядерной архитектуры процессоров.
Для реализации алгоритма использован язык C#, так как платформа .NET предоставляет средства разработки и синхронизации многопоточных приложений, а также за счет компиляции исходного кода в байт-код CIL (Common Intermediate Language) с последующим исполнением виртуальной машиной даёт возможность создания кроссплатформенного приложения [20].
Одним из вариантов оптимизации является распределении просчета параметров соседних вершин по потокам. Данный способ также является вариативным и есть несколько путей реализации: распределение на 2 потока, в котором первый обрабатывает 1 – 4 вершины, второй вершины 5 – 8; распределение на 4 потока, обрабатывающих по 2 соседа; распределение на 8 потоков, каждый из которых обрабатывает по одной вершине. Все варианты данного метода редактируют общие списки, поэтому доступ к памяти синхронизируется мьютексами [19].
Для тестирования разработано поле со множеством препятствий и несколькими возможными маршрутами, чтобы усложнить работу для программы. Алгоритм проверялся на двух разных процессорах, поддерживающих многопоточность – Intel Penuim CPU G2020 @ 2.90 GHz, 2.90 GHz и Intel Pentium CPU B970 @ 2.30 GHz, 2.30 GHz. Однако тесты показали ухудшение производительности как на коротких интервалах, так и на длинных маршрутах. При распределении на 2 потока ухудшение быстродействия незначительно, на 4 потоках снижение результативности является более серьёзным, 8-поточная же реализация дала критическое падение производительности. Результаты теста показаны на рисунке 3.
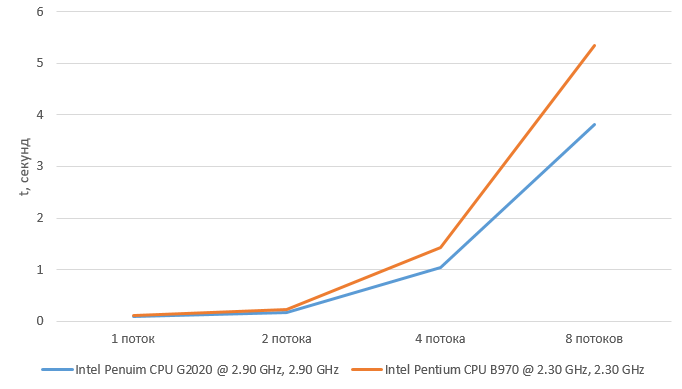
Рисунок 3 – Диаграмма времени выполнения разных многопоточных реализаций
При помощи средств профилирования Microsoft Visual Studio 2013 сформирована статистика и определена конкуренция потоков за ресурсы [21]. Диаграмма конкуренции при реализации программы в 8 потоков представлена на рисунке 4.
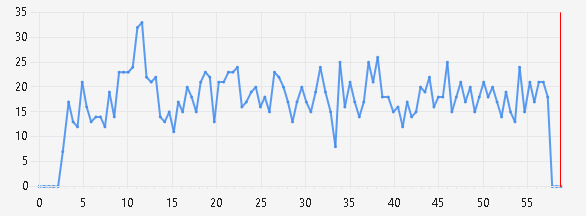
Рисунок 4 – Диаграмма конкуренции 8 потоков при просчете одного маршрута
Данная диаграмма отображает интенсивность конкуренции в секунду и показывает конфликты ресурсов. Повышенный уровень конкуренций негативно влияет на производительность, так как потоки простаивают в ожидании. Как видно из рисунка, частота конкуренции крайне высока - 33 состязания. Таким образом, метод распределения вершин по потокам имеет следующие недостатки: общий список осмотренных вершин, доступ к которому предоставляется синхронизацией мьютексами, что увеличивает задержку при одновременном обращении к одному участку памяти, а также синхронизация всех потоков в одном участке, при котором потоки ждут завершения друг друга. Данный недостаток возникает при каждом перемещении на соседнюю вершину, в связи с чем происходит серьёзное падение производительности.
При выполнении алгоритма на 2 потоках также были выявлены конкуренции. Результат представлен на рисунке 5.
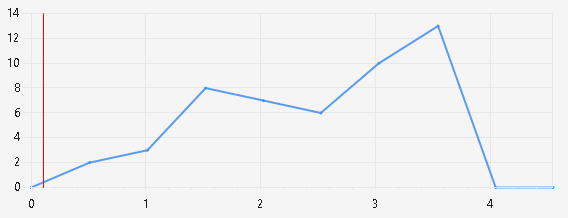
Рисунок 5 – Диаграмма конкуренции 2 потоков
Однако, по сравнению с 8-поточной реализацией, конкуренция ресурсов меньше. Средствами профилировщика определено 10 состязаний.
Альтернативным вариантом является одновременный расчет пути сразу нескольких объектов. В этом случае задаются попарно несколько стартовых и конечных точек. При этом каждый поток имеет свой участок памяти – все переменные в функции являются локальными. Каждому маршруту соответствует свой поток, который формирует собственный список открытых и закрытых вершин. Для испытания такой реализации разработано несколько вариантов выполнения программы: для одного, двух, четырех и восьми маршрутов [22]. Тестирования проведены на процессорах Intel Penuim CPU G2020 @ 2.90 GHz, 2.90 GHz и Intel Pentium CPU B970 @ 2.30 GHz, 2.30 GHz. Результаты теста показаны на рисунке 6.
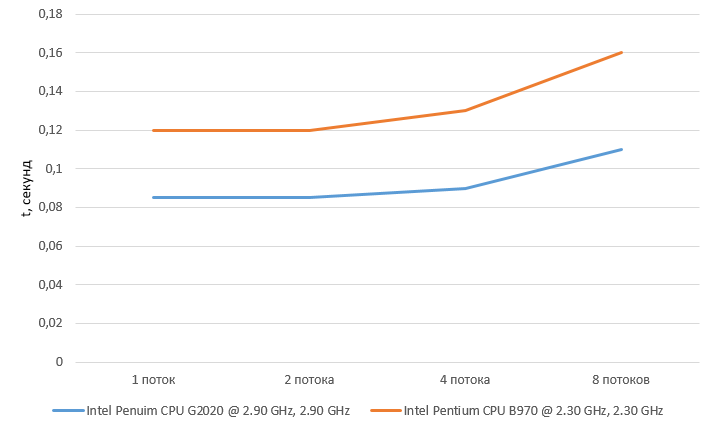
Рисунок 6 – Диаграмма времени выполнения разных многопоточных реализаций
Альтернативный вариант, в котором каждый поток просчитывает свой маршрут, напротив показал существенный прирост во времени выполнения – за одно и то же время просчитываются два и четыре маршрута.
Сравнительный анализ двух методов проведен на процессоре Intel Pentium CPU B970 @ 2.30 GHz, 2.30 GHz. Время выполнения отображено на рисунке 7.
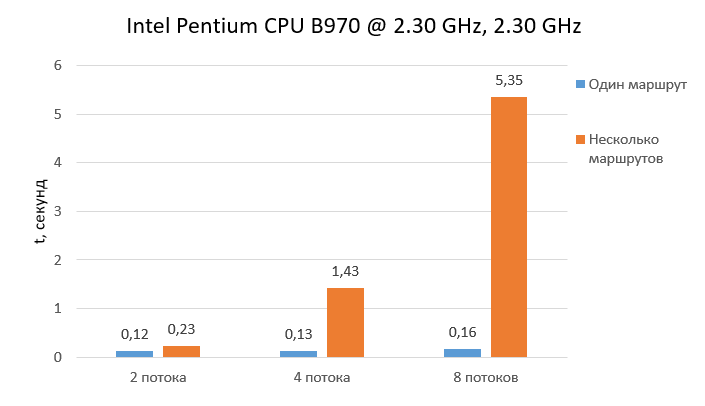
Рисунок 7 – Время выполнения методов
В левом столбце отображено время вычисления одновременно нескольких маршрутов, в правом – распределение просчета вершин единого пути по потокам. Время выполнения однопоточной реализации составляет 0,12 мс.
Для 2-поточной реализации сформирована статистика и определена конкуренция потоков за ресурсы [21]. Диаграмма конкуренции отображена на рисунке 8.
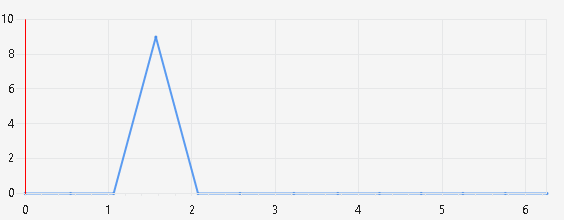
Рисунок 8 – Диаграмма конкуренции 2 потоков при просчете нескольких маршрутов
Как видно из рисунка, средства профилировщика показали отсутствие состязаний за исключением синхронизации в главном потоке. Существенный плюс данного варианта состоит в отсутствии редактируемого всеми потоками одного и того же участка памяти, а также необходимости постоянного ожидания потоками друг друга в цикле [22].
Таким образом, разработаны и протестированы методы многоядерного ускорения алгоритма А*. Метод, в котором потоки циклически просчитывают параметры соседних вершин, показал падение производительности. Это связано с конкуренцией за общие участки памяти, а также из-за синхронизации завершения потоков после просчета соседей каждой вершины. Метод распределения траектории на несколько маршрутов показал существенное улучшение производительности.
Исходя из исследования, можно определить два метода оптимизации на основе просчета разных путей:
1. Использование методов декомпозиции одного маршрута на несколько участков и мультипоточный расчет каждой части.
2. Предварительный расчет пути.
Первый метод представляет собой разделение единого маршрута на множество частей, после чего производится вычисление оптимального пути для каждого участка. Недостатком этого метода является сходимость краев маршрута, а также дополнительные затраты на вычисления необходимых промежуточных точек.
Второй метод больше подходит для прогнозирования траектории движения. Его суть состоит в том, чтобы предварительно рассчитывать маршруты из тех точек, в которые подвижный объект может попасть через определенный интервал времени. Таким образом, для объекта сразу будет предоставлен готовый путь, куда бы он не повернул.
Просчет маршрута необходимо выполнять во время передвижения, чтобы сообщать объекту действия согласно вычисляемой траектории. Это необходимо для оптимального и своевременного достижения конечной цели. Пример маршрута между точками A и B показан на рисунке 9.
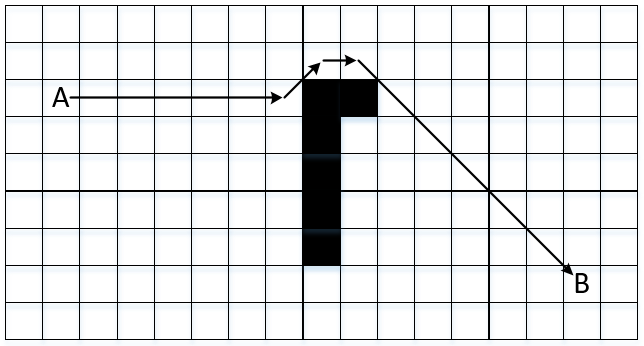
Рисунок 9 – Оптимальный маршрут передвижения
Единица тяжелой инженерной гусеничной техники может менять направление движения, а также регулировать скорость. Необходима возможность поворота на 45° и на 90°, а также ускорение или торможение. Поворот на 45° осуществляется отключением от трансмиссии той гусеницы, в направлении которой необходимо повернуть. Для крутых поворотов на 90° требуется дополнительное торможение гусеницы. Скорость изменяется переключением передачи и с помощью педали [23]. Таким образом, возникает необходимость составить очередность действий для достижения цели. Список действий формируется с использованием метода мультифиниша. При продолжительном однонаправленном отрезке появляется возможность ускорения для улучшения временной составляющей движения. После достижения максимальной скорости давление на педаль не меняется, передвижение остаётся равномерным. Перед поворотами на 45° отключается одна гусеница, для 90° гусеница тормозится. Если дальнейший путь прямолинейный, возобновляется прежняя скорость движения. Перед финишем необходимо торможение [24].
Таким образом, для следования траектории определен алгоритм выбора последовательности действий. В соответствии с каждым действием возникает необходимость предварительного просчета пути из точки, в которую может попасть единица тяжелой техники. Для повышения эффективности вычислений необходимо распараллеливание на GPU при помощи CUDA. В отличие от CPU, графические процессоры нацелены на максимальную многопоточность.
6. Использование графического процессора для исследования оптимизации прогнозирования поведения
Графический процессор GPU – это устройство, которое выполняет графическую обработку (рендеринг). Сегодня GPU эффективно применяется для обработки данных в компьютерной графике. Основной особенностью является архитектура, которая максимально нацелена на увеличение скорости расчёта.
Для графического просчета необходима параллельная обработка данных. Поэтому GPU изначально мультипоточен. Архитектура спроектирована так, чтобы использовать большое количество нитей. Если современные CPU содержат от 2 до 128 ядер, то в графическом процессоре их количество достигает несколько тысяч. CPU лучше работает с последовательными задачами, при большом же объеме потоков информации преимущество имеет GPU.
Для разработки программ, использующих GPU, применяется технология CUDA – программно-аппаратная архитектура параллельных вычислений от компании Nvidia. В технологию CUDA включен унифицированный шейдерный конвейер, позволяющий программе задействовать любое АЛУ в GPU [25].
Таким образом, видеокарта является параллельной системой, поэтому необходимо провести сравнительный анализ ускорения прогнозирования поведения при помощи GPU.
Выводы
Таким образом, для прогнозирования оптимальной траектории движения был использован алгоритм А*, эффективно использующий эвристику. Метод, в котором потоки циклически просчитывают параметры соседних вершин, показал падение производительности – распределение маршрута на 2, 4 и 8 потоков показало ухудшение результата по сравнению с однопоточной реализацией. Это связано с конкуренцией за общие участки памяти, а также из-за синхронизации завершения потоков после просчета соседей каждой вершины. Метод распределения траектории на несколько маршрутов показал улучшение производительности из-за разделяемой памяти. Это связано с раздельной памятью и отсутствием необходимости ожидания потоков. Комбинация данного метода с декомпозицией единого маршрута на участки имеет недостаток в сходимости краёв маршрутов.
Использование графических процессоров может ускорить процесс. Дальнейшие исследования позволят получить следующую аналитическую информацию:
– скорость прогнозирования траектории с использованием GPU;
– минимальная и максимальная степень дискретизации рабочего поля, его размеры для своевременного выполнения алгоритма;
– сравнительные характеристики различной реализации параллельного алгоритма;
– сравнительный анализ выполнения параллельного алгоритма на CPU и GPU;
– целесообразность использования GPU для предсказания поведения.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: июнь 2018 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Marco Pinter: Toward More Realistic Pathfinding – [Электронный ресурс]. – Режим доступа: https://www.gamasutra.com/...
- Amit Patel: Amit’s A* Pages [Электронный ресурс]. – Режим доступа: http://theory.stanford.edu/...
- Akos Cservenak, Tamas Szabo. Dynamical Modelling of Vehicle’s Maneuvering. In book: Vehicle and Automotive Engineering: Proceedings of the JK2016, Miskolc, Hungary / editors: Jarmai Karoly, Bollo Betti (Eds.), 2017. – 516 p.
- Avi Bleiweiss. GPU Accelerated Pathfinding / In proceedings of Graphics Hardware, 2008, Pages 65 – 74, 2008.
- RAFIA INAM: A* Algorithm for Multicore Graphics Processors [Электронный ресурс]. – Режим доступа: http://publications.lib.chalmers.se/...
- Maximilian Gotzinger, Martin Pongratz, Amir M. Rahmani and Axel Jantsch: Parallelized Flight Path Prediction Using a Graphics Processing Unit [Электронный ресурс]. – Режим доступа: https://www.researchgate.net/...
- The Essential Resource for GPU Developers. Official NVIDIA site – [Электронный ресурс]. – Режим доступа: https://developer.nvidia.com
- Аноприенко А. Я., Кривошеев С. В. Разработка подсистемы моделирования движения судна по заданной траектории // Научные труды Донецкого национального технического университета. Выпуск 12. Серия
Вычислительная техника и автоматизация
. – Донецк, ДонГТУ, ОООЛебедь
, 1999. С. 197–202. - Аноприенко А. Я., Кривошеев С. В. Моделирование динамики речного судна на базе системы Matlab/Simulink //
Прогрессивные технологии и системы машиностроения
: Международный сборник научных трудов. – Донецк: ДонГТУ, 2000. Вып. 9. С. 13–20. - Кривошеев С. В. Исследование эффективности параллельных архитектур вычислительных систем для расчета параметров движения транспортного средства // Научные труды Донецкого национального технического университета. Выпуск № 1(10)-2(11). Серия
Проблемы моделирования и автоматизации проектирования
. – Донецк, ДонНТУ, 2012. С. 207–214. - Кондратенко А. В. Моделирование алгоритмов определения координат в модуле отображения систем логистики [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/...
- Гапечкин А. И. Анализ поведения подвижного объекта в замкнутом пространстве [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/...
- Паршин А. Н. Вычисление координат подвижного объекта [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/...
- Порицкий А. В. Алгоритмы генерации траектории движения подвижного объекта [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/...
- Водолазский Д. С. Разработка параллельных алгоритмов движения 3D объектов [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/...
- Варич М. В. Разработка модели параллельной вычислительной системы для расчета параметров подвижного объекта [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/...
- Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн. Алгоритмы: построение и анализ – 3-е изд. – М.:
Вильямс
, 2013. – С. 499–502. - Койбаш А. А., Кривошеев С. В. Прогнозирование траектории движения подвижного объекта распределенного симулятора тяжелой инженерной техники. В кн.: Информатика, управляющие системы, математическое и компьютерное моделирование (ИУСМКМ – 2016): материалы VII междунар. науч.-техн. конф., Донецк, 2016. / редкол. А. Ю. Харитонов и др. Донецк: ДонНТУ, 2016. С. 343–346.
- Hughes C., Hughes T. Professional Multicore Programming: Design and Implementation for C++ Developers. – Indianapolis: Wiley Publishing, Inc., 2008 – 648 p.
- Кристиан Нейгел и др. C# 5.0 и платформа .NET 4.5 для профессионалов. – М.:
Диалектика
, 2013. – 1440 с. - Койбаш А. А., Кривошеев С. В. Подсистема прогнозирования траектории движения подвижного объекта распределенного симулятора тяжелой инженерной техники. В кн.: Программная инженерия: методы и технологии разработки информационно-вычислительных систем (ПИИВС – 2016): сборник научных трудов I научно-практической конференции (студенческая секция), Донецк, 2016. / Донецк: ДонНТУ, 2016. С. 262–265.
- Койбаш А. А., Кривошеев С. В. Пути снижения времени прогнозирования траектории движения подвижного объекта распределенного симулятора тяжелой инженерной техники. В кн.: Современные тенденции развития и перспективы внедрения инновационных технологий в машиностроении, образовании и экономике: материалы IV междунар. науч.-практ. конф., Азов 2017. / редкол. С. В. Жуков и др. Азов: Технологический институт (филиал) ДГТУ, 2017. С. 51–54.
- Анилович В. Я., Водолажченко Ю. Т. Конструирование и расчет сельскохозяйственных тракторов. Справочное пособие. Изд. 2 переработанное и доп. – М.:
Машиностроение
, 1976. – 456 с. - Койбаш А. А., Кравченко А. Г. Эффективность использования многоядерных систем для прогнозирования траектории движения подвижного объекта распределенного симулятора тяжелой инженерной техники. В кн.: Информатика, управляющие системы, математическое и компьютерное моделирование (ИУСМКМ – 2017): материалы VIII междунар. науч.-техн. конф., Донецк, 2017. / редкол. Ю. К. Орлов и др. Донецк: ДонНТУ, 2017. С. 622–625.
- Джейсон Сандерс, Эдвард Кэндрот Технология CUDA в примерах. Введение в программирование графических процессоров. – ДМК Пресс, 2011. – С. 21.