

Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель исследования
- 3. Общие положения
- 3.1 Актуальность
- 3.2 Автоматизированный перевод
- 3.2.1 Статический машынный перевод
- 3.2.2 Нейронный машынный перевод
- 3.3 Обзор существующих систем
- 4. Математическая постановка
- 4.1 Выбор архитектуры
- 4.2 Режимы работы рекуррентной сети
- 4.3 Представление текста
- Способы решения
- 5.1 Реккурентные нейронные сети
- 5.2 LSTM
- 5.3 Представление текста в цифровом виде
- 5.4 Среда разработки
- Список источников
Введение
Перевод, как и язык, сегодня остаётся самым универсальным средством общения между людьми. Он необходим и при межличностных контактах, и при построении практической производственной деятельности, и в общении между народами. Важность перевода особенно появляется при диалоге культур. Нарастающая глобализация мировой экономики и укрепляющиеся международные отношения между субъектами разных стран стимулируют всё большее количество компаний, заинтересованных в международном сотрудничестве, в увеличении своей эффективности и профессионализма в межкультурной коммуникации и деловом общении. Переводческая деятельность затрагивает значительное количество сфер деятельности человека, играет важную роль в развитии науки и техники, напрямую способствуя прогрессу человечества и предоставляя возможность общения и передачи опыта, преодолевая языковые барьеры.
Деятельность переводчика представляет из себя сложное по строению лингвистическое явление. Качественное исполнение своих обязанностей требует от него наличия как практических, так и теоретических знаний. Необходимость ориентироваться в современных реалиях профессии, умение использовать и эффективно применять новейшие системы — требования, всё чаще предъявляемые к специалистам в наши дни.
Современный переводчик должен обладать не только обширными лингвистическими знаниями, но и быть технически подкованным.
В связи с глобализацией бизнеса, появлением новых типов контента и взрывным ростом потребления информации, индустрия переводов, как и многие другие, претерпевает стремительные изменения. Спрос на перевод растёт достаточно быстро и вместе с ним повышается необходимость применения технологий, которые повысят производительность переводческих процессов и позволят удовлетворить этот спрос. В настоящее время в переводческой деятельности широко применяются системы автоматизированного перевода.
Автоматизированный перевод как таковой включает себя целый ряд научных дисциплин от лингвистики до математики и кибернетики. Инструменты автоматизированного перевода значительно различаются по своей структуре и методам работы. Их общей чертой является то, что они служат для улучшения условий труда переводчика, зачастую производя автоматическое генерирование желаемой части текста на желаемом языке под контролем специалиста, используя особые правила перевода грамматических структур. Степень контроля специалистом этих инструментов в процессе перевода также может значительно различаться. Эффективность реализации данных систем зависит от знаний и уровня профессиональной подготовки пользователя, а также от способности оперативно усваивать новое программное обеспечение.
Перевод синтаксических конструкций — одна из основных проблем и сложностей переводческой деятельности. Именно связная и эквивалентная трансформация данных конструкций разного типа и представляет основной вызов в работе специалиста. Данная работа предназначена для исследования эффективности автоматизированного перевода как инструмента для решения этой проблемы.
1. Актуальность темы
Актуальность работы обусловлена необходимостью более глубокого исследования программ и инструментов автоматизированного перевода и методов их функционирования, значительным числом новых тенденций в компьютерной лингвистике. Потенциальные преимущества использования систем автоматизированного перевода не являются полностью исследованными и интегрированными в переводческую деятельность. Число требований и навыков, которыми должен обладать профессиональный переводчик, растёт из года в год.
2. Цель исследования
Цель исследования состоит в том, чтобы изучить специфику, процессы и механизмы применения автоматизированного перевода при переводе синтаксических конструкций с английского языка на русский, разработать автоматизированный переводчик в сфере IT–технологий.
3. Общие положения
3.1 Актуальность
Актуальность проекта обусловлена в необходимости создания переводчика в сфере технических текстов. Существующие системы перевода направлены на разговорную речь и не всегда переводят технические тексты правильно. Задачей проекта является разработать переводчик, работающий исключительно в IT–технологий.
3.2 Автоматизированный перевод
Автоматизированный перевод — перевод текстов на компьютере с использованием компьютерных технологий.[1] Инструменты автоматизированного перевода значительно различаются по своей структуре и методам работы. Их общей чертой является то, что они служат для улучшения условий труда переводчика, зачастую производя автоматическое генерирование желаемой части текста на желаемом языке под контролем специалиста, используя особые правила перевода грамматических структур.
3.2.1 Статический машинный перевод
Статистический машинный перевод — разновидность машинного перевода, где перевод генерируется на основе статистических моделей, параметры которых являются производными от анализа двуязычных корпусов текста (text corpora).[2]
Разработчики систем машинного перевода для улучшения качества вводят некоторые сквозные
правила, тем самым превращая
чисто статистические системы в Гибридный машинный перевод. Добавление некоторых правил, то есть создание гибридных
систем, несколько улучшает качество переводов, особенно при недостаточном объёме входных данных, используемых
при построении индекса машинного переводчика.
3.2.2 Нейронный машинный перевод
Нейронный машинный перевод — это подход к машинному переводу, в котором используется большая искусственная нейронная сеть.[3]
Модели NMT используют глубинное обучение и обучение признакам. Для их работы требуется лишь малая часть памяти по сравнению с традиционными системами статистического машинного перевода (SMT). Кроме того, в отличие от традиционных систем перевода, все части модели нейронного перевода обучаются совместно (от начала до конца), чтобы максимизировать эффективность перевода.
Двунаправленная рекуррентная нейронная сеть (RNN), также известная как кодировщик, используется нейронной сетью для кодирования исходного предложения для второй рекуррентной сети, также известной как декодировщик, которая используется для предсказания слов в конечном языке.
3.3 Обзор существующих систем
Google Translate
Google Переводчик — веб–служба компании Google, предназначенная для автоматического перевода части текста или веб–страницы на другой язык.[4]
Google использует собственное программное обеспечение. Предполагается, что компания использует самообучаемый алгоритм машинного перевода. В марте 2017 года Google полностью перевела движок перевода на нейросети для более качественного перевода. Из–за того, что выдача вариантов контролируется статистическим алгоритмом, при переводе обычных общеупотребительных слов Google Переводчик может предлагать в числе возможных вариантов нецензурные слова. На результат выдачи также можно повлиять, массово предлагая некий, в том числе заведомо неверный вариант перевода. Google Переводчик предлагает перевод с любого поддерживаемого языка на любой поддерживаемый, но в большинстве случаев реально выполняет перевод через английский. Иногда качество от этого сильно страдает. Например, при переводе с польского на русский обычно нарушаются падежи (даже когда они в русском и польском одинаковы). Есть также языки, которые проходят двойной процесс обработки перевода сначала через близко–родственный язык, потом через английский.
Yandex Translate
Яндекс.Переводчик — веб–служба компании Яндекс, предназначенная для перевода части текста или веб–страницы на другой язык.[5]
В службе используется самообучаемый алгоритм статистического машинного перевод, разработанный специалистами компании. Система строит свои словари соответствий на основе анализа миллионов переведённых текстов. Текст для перевода компьютер вначале сравнивает с базой слов, затем с базой моделей языка, стараясь определить смысл выражения в контексте. Переводчик от Яндекса, подобно другим инструментам автоматического перевода, имеет свои ограничения. Этот инструмент имеет целью помочь читателю понять общий смысл содержания текста на иностранном языке, он не предоставляет точных переводов. Постоянно ведётся работа над качеством перевода, разрабатываются переводы на другие языки.
DeepL
DeepL — онлайн–переводчик, работающий на основе машинного перевода. Запущен в работу компанией DeepL GmbH
из Кёльна в августе 2017 года.[6] Сервис позволяет переводить 72 языковые пары на немецком, английском,
французском, голландском, польском, русском, итальянском, испанском, португальском. Служба использует
сверточные нейронные сети, обученные на основе базы Linguee. Перевод генерируется с помощью суперкомпьютера,
вычислительная мощность которого составляет 5,1 петафлопс, работающего в Исландии на электричестве,
производимом гидроэлектростанцией. Свёрточные нейронные сети, как правило, несколько лучше подходят
для перевода длинных последовательных словосочетаний, но до сих пор не использовались конкурентами,
которые предпочитали использовать рекуррентные нейронные сети либо статистический перевод.
4. Математическая постановка
4.1 Выбор архитектуры
Существует множество видов архитектур нейронных сетей.
Популярными из них являются:
- Рекуррентные нейронные сети (это класс нейронных сетей, которые хороши для моделирования последовательных данных, таких как временные ряды или естественный язык);[7]
- Свёрточные нейронные сети (специальная архитектура искусственных нейронных сетей, нацеленная на эффективное распознавание образов, входит в состав технологий глубокого обучения);[8]
- Комбинированные нейронные сети (такие нейронные сети способны понимать, что находится на изображении, и описывать это. И наоборот: рисовать изображения по описанию).
Для построения переводчика необходима работа с последовательностями. Для этого будет использоваться рекуррентная нейронная сеть.
4.2 Режимы работы рукуррентной сети
Рекуррентная нейронная сеть может работать в различных режимах:
- Один на вход – один на выход;
- Один на вход – последовательность выходов;
- Последовательность входов – последовательность выходов;
- Последовательность входов – один на выход.
На вход нейронного переводчика может входить как слово, так и целые предложения, а также текста.
Следовательно, на вход черного ящика
должна входить последовательность, и на выходе должна быть последовательность.
4.3 Представление текста
Текст необходимо представлять в цифровом виде. Существует три способа кодирования:
- Числовое кодирование;
- One hot encoding (представление в двоичном векторе);
- Плотное векторное представление (представление в векторе любых чисел).
Так как на вход будет подаваться последовательность, необходимо использовать векторное представление. Целесообразно использовать плотное векторное представление, т.к. размер данного вектора меньше.
5 Способы решения
5.1 Рекуррентные нейронные сети
Важной особенностью машинного перевода, а также любой другой задачи, связанной с естественным языком, является переменная длина входа X = (x1, x2, …, xT) и выхода Y = (y1, y2, …, yT´). Другими словами, T и T´ не являются фиксированными.
Чтобы работать со входом и выходом переменной длины, необходимо использовать рекуррентную нейронную сеть (РНС, recurrent neural network, RNN). Широко применяемые нейронные сети прямого распространения (feedforward neural network), такие как сверточные нейронные сети (convolutional neural network), не хранят информацию о внутреннем состоянии, используя только собственные параметры сети. Каждый раз, когда элемент данных подается в нейронную сеть прямого распространения, внутреннее состояние сети (то есть функции активации скрытых нейронов) вычисляется заново. При этом на него не оказывает влияние состояние, вычисленное при обработке предыдущего элемента данных. В отличие от этого, РНС сохраняет свое внутренне состояние при чтении входной последовательности элементов данных, являющейся в нашем случае последовательностью слов. Следовательно, РНС способна обрабатывать входные данные произвольной длины.
Основная идея РНС заключается в том, чтобы с помощью рекурсии сформировать из входной последовательности символов вектор фиксированной размерности. Предположим, что на шаге t мы имеем вектор ht–1, представляющий собой историю всех предыдущих символов. РНС вычислит новый вектор ht (то есть свое внутреннее состояние), который объединяет все предыдущие символы (x1, x2, …, xt–1), а также новый символ xt с помощью:
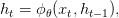
где φΔ – функция, параметризованная посредством θ, которая принимает на входе новый символ xt и историю ht–1 до (t–1)–го символа. Изначально мы можем смело предположить, что h0 – нулевой вектор.
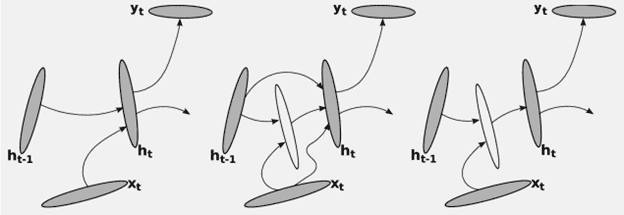
Рисунок 1 – Рекуррентная нейронная сеть
Рекуррентная функция активации φ обычно реализуется, например, как простое аффинное преобразование (affine transformation), за которым следует поэлементная нелинейная функция:
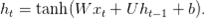
В этом выражении присутствуют следующие параметры: входная весовая матрица W, рекуррентная весовая матрица U и вектор смещения (bias vector) b. Следует отметить, что это не единственный вариант. Существует обширное пространство для разработки новых рекуррентных функций активации.
5.2 LSTM
Долгая краткосрочная память (Long short–term memory; LSTM) – особая разновидность архитектуры рекуррентных нейронных сетей, способная к обучению долговременным зависимостям.[9] LSTM разработаны специально, чтобы избежать проблемы долговременной зависимости. Запоминание информации на долгие периоды времени – это их обычное поведение, а не что–то, чему они с трудом пытаются обучиться.
Структура LSTM напоминает цепочку, но модули выглядят иначе. Вместо одного слоя нейронной сети они содержат целых четыре, и эти слои взаимодействуют особенным образом.
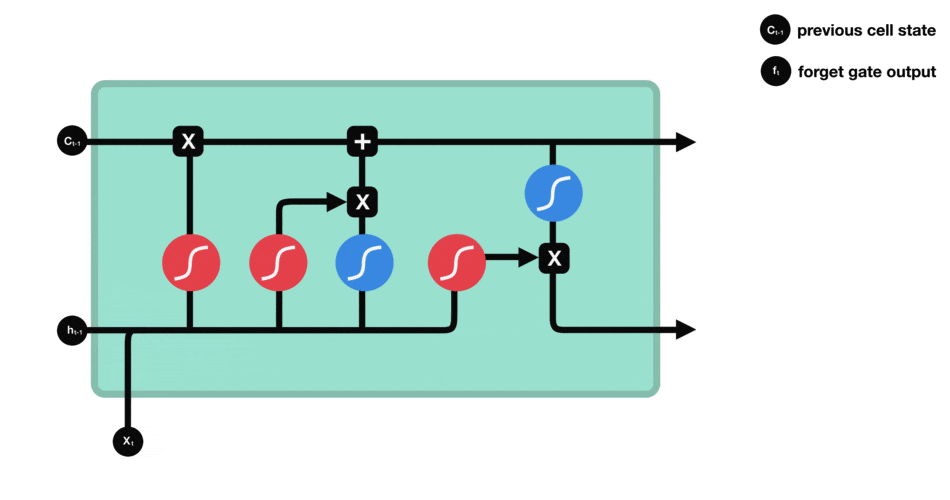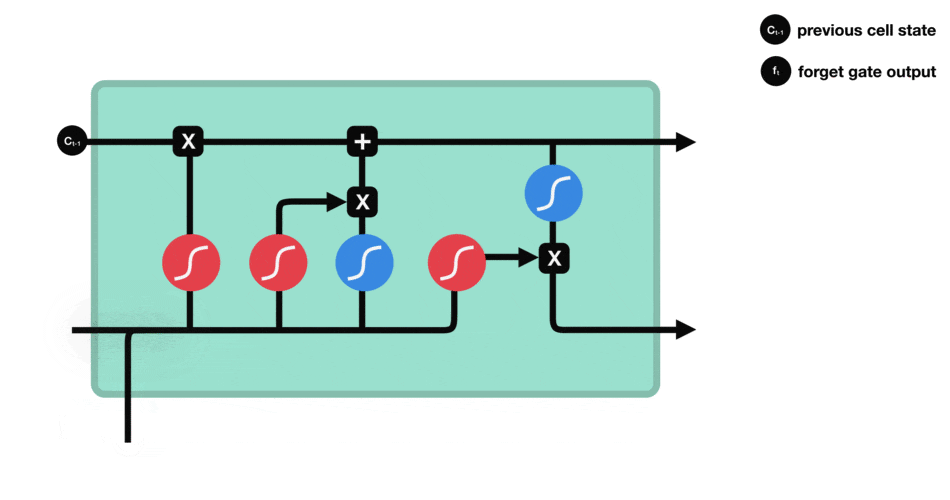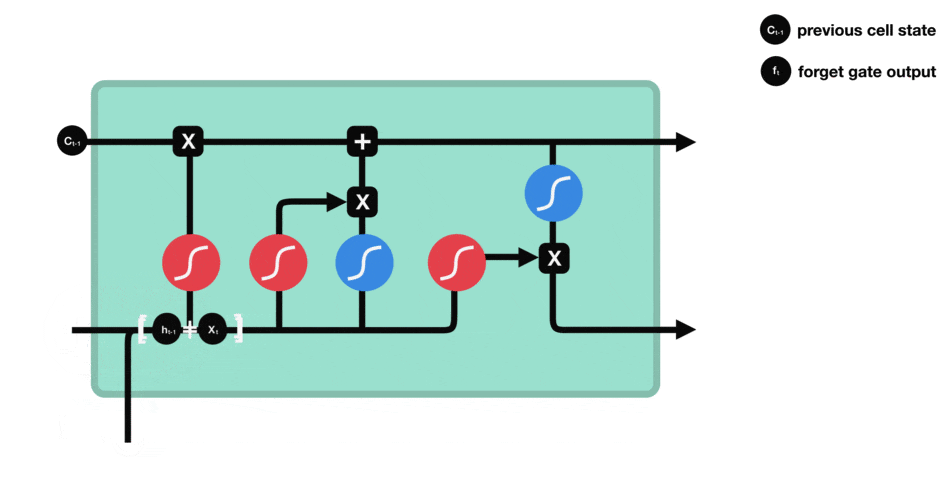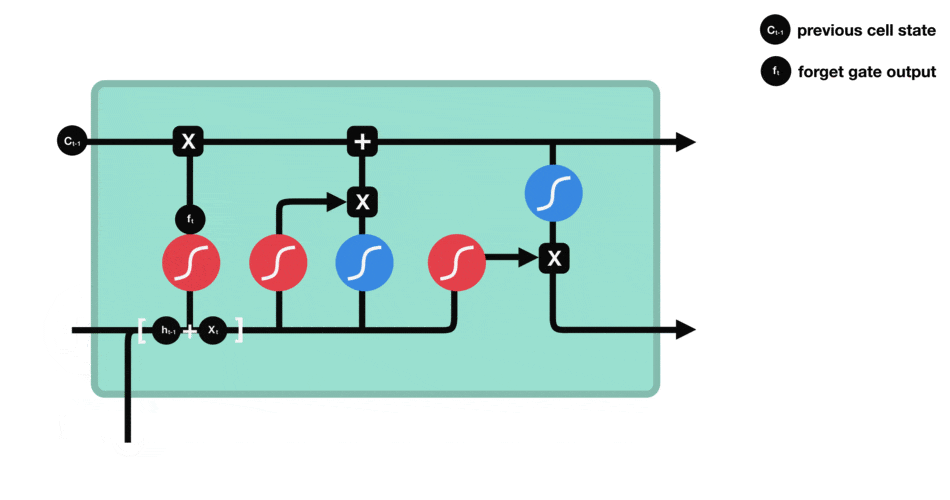
Рисунок 2 – Сеть LSTM
Ключевой компонент LSTM – это состояние ячейки (cell state) – горизонтальная линия, проходящая по верхней части схемы.
Состояние ячейки напоминает конвейерную ленту. Она проходит напрямую через всю цепочку, участвуя лишь в нескольких линейных преобразованиях. Информация может легко течь по ней, не подвергаясь изменениям.
5.3 Представление текста в цифровом виде
Нейронная сеть умеет работать только с числами. Она выполняет с ними различные математические операции. Поэтому, когда мы используем нейронные сети для анализа данных, данные не обходимо перевести в набор чисел.
Работа с изображениями представляет собой набор чисел, которые соответствуют интенсивности пикселей от 0 до 255.
В работе со структурированными данными (например таблицы) возможны два варианта:
- Если данные в числовом виде, с ними ничего делать не нужно;
- Если данные в категориальном виде (например пол мужчины или женщины), то такие данные представляются в виде векторов one hot encoding.
Для работы с текстом, необходимо разбить текст на отдельные части, каждая из которых будет представляться в цифровом виде отдельно.
Можно разбить текст на:
- Символы (буквы, цифры, знаки препинания и т.п. и в числовом виде представлять отдельный символ);
- Слова (ставить число или набор чисел не отдельным символам, а целым словам);
- Предложения (в виде чисел представляются целые предложения).
После разбиения текста на отдельные токены, необходимо каждый токен преобразовать в числовой вид.
Для преобразования токенов в числовой вид можно использовать:
- Числовое кодирование (каждому токену присваиваем отдельный код: частота (с которой токен встречается в тексте), или использовать различные кодировки (ASCII, UTF–8 и т.п. (каждому символу алфавита соответствует некоторый числовой код)));
- Каждому токену соответствует не одно число, а вектор чисел – one hot encoding (используется на выходе из нейронных сетей в задачах классификации и для представления правильных ответов при работе с учителем). В этом случае вектор содержит столько чисел, сколько можно использовать токенов и все элементы вектора равны нулю, кроме того, который соответствует нужному токену;
- Использование плотного векторного представления. В этом случае, каждому числу ставится не одно число, а вектор, но размерность вектора ниже, чем one hot encoding, за счет того, что в этом векторе используются не только нули и единицы, а любые числа.
5.4 Среда разработки
Разработка подсистемы будет разрабатываться на языке Python с использование Google Colab. Google Colab – это сервис, который позволяет запускать Jupyter Notebook–ки с бесплатым доступом к видеокарте Nvidia K80.
Jupyter Notebook – это командная оболочка для интерактивных вычислений на python.
Список источников
- Автоматизированный перевод [electronic resource] // Интернет ресурс – Режим доступа: https://dic.academic.ru/dic.nsf/ruwiki/30223
- Статический машинный перевод [electronic resource] // Интернет ресурс – Режим доступа: https://intellect.icu/mashinnyj-perevod-vidy-i-osobennosti-9510
- Нейронный машинный перевод [electronic resource] // Интернет ресурс – Режим доступа: http://ru.wikipedia.org/wiki/Нейронный_машинный_перевод
- Google Переводчик [electronic resource] // Интернет ресурс – Режим доступа: https://ru.wikipedia.org/wiki/Google_Переводчик
- Yandex Переводчик [electronic resource] // Интернет ресурс – Режим доступа: https://habr.com/ru/company/yandex/blog/576438/
- DeepL [electronic resource] // Интернет ресурс – Режим доступа: https://www.deepl.com/ru/home
- Рекуррентные нейронные сети [electronic resource] // Интернет ресурс – Режим доступа: https://habr.com/ru/post/487808/
- Сверточные нейронные сети [electronic resource] // Интернет ресурс – Режим доступа: https://medium.com/@balovbohdan/сверточные-нейронные-сети
- LSTM [electronic resource] // Интернет ресурс – Режим доступа: https://habr.com/ru/company/wunderfund/blog/331310/