|
Коммуникационные особенности матрично–векторных операций могут быть эффективно использованы при
решении задачи Коши вида (3.1) для системы обыкновенных линейных дифференциальных уравнений.
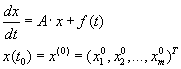 (3.1) (3.1)
В соответствии с одним из методов решение задачи можно получить по правилу Рунге-Кутта вида (3.2). Эта
формула определяет итерационный процесс, который сводится к операциям матрично-векторной
арифметики [2, c.1].
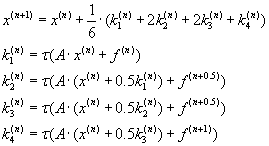 (3.2) (3.2)
Все промежуточные коэффициенты ki могут быть вычислены только последовательно. Параллелизм может
быть реализован при расчёте каждого из коэффициента. Это может быть достигнуто за счёт использования
параллельных матрично–векторных арифметических операций, описанных выше.
Альтернативный метод решения задачи Коши по правилу Рунге-Кутта – расчёт полного оператора (матрицы)
перехода. Эта операция выполняется предварительно и единожды (до выполнения итераций метода) по
формуле (3.3). Таким образом, весь итерационный процесс сводится к серии последовательных умножений
матрицы на вектор [2, c.3-5].
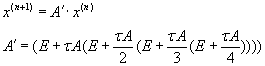 (3.3) (3.3)
Преимущество подхода с расчётом матрицы перехода проявляется при большом количестве итераций метода
Рунге–Кутта. Соответственно для определённого количества итераций лучшие показатели будет демонстрировать
подход с расчётом промежуточных величин.
Характерная черта методов Рунге-Кутта: итерационный процесс поиска решения задачи Коши. Параллелизм
реализуется в процессе вычислений на каждом шаге при расчёте промежуточных величин. Вычислительная
зависимость промежуточных величин в общем случае не позволяет осуществлять одновременный расчёт
приближений решения на различных шагах методу Рунге–Кутта.
Параллелизм алгоритма по методу Рунге–Кутта с расчётом промежуточных коэффициентов на шаге может
быть реализован на этапе выполнения матрично–векторных операций. Так вычислительные затраты шага
параллельного алгоритма будут определяться формулой (3.4). Время выполнения параллельной версии
N–шагового метода Рунге–Кутта определяется выражением (3.5). В качестве базового алгоритма вычисления
матрично–векторных произведений выбран алгоритм Кэннона, сохраняющий отображение матрицы–операнда.
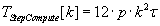 (3.4) (3.4)
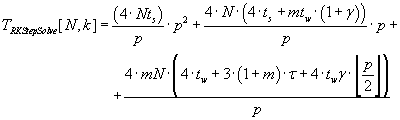 (3.5) (3.5)
Величины ускорения и эффективности использования процессоров параллельного алгоритма определяется
формулами (3.6) и (3.7) соответственно.
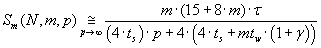 (3.6) (3.6)
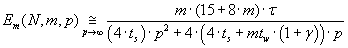 (3.7) (3.7)
Чтобы отойти от расчёта промежуточных коэффициентов на каждом шаге метода Рунге–Кутта необходимо
ввести в алгоритм оператор (матрицу) перехода для определения вектора неизвестных на текущей итерации.
Расчёт матрицы можно распараллелить путём использования алгоритма с неизменным отображением
матрицы–результата. Расчёт решения на очередной итерации можно выполнять путём вычисления
матрично–векторного произведения по алгоритму Кэннона с неизменным отображением матрицы A.
Время выполнения параллельного алгоритма расчёта матрицы перехода по формуле (3.3) определяется
выражением (3.8).
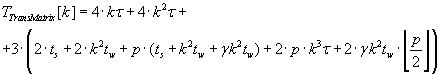 (3.8) (3.8)
Формула (3.9) отражает эквивалент функции ускорения параллельного алгоритма для больших
значений p. Эффективность использования процессоров параллельным алгоритмом определяется
формулой (3.10).
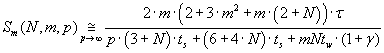 (3.9) (3.9)
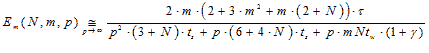 (3.10) (3.10)
Пусть алгоритм решения задачи Коши для системы линейных ОДУ с вычислением промежуточных данных по
методу Рунге–Кутта будет обозначен через RKStepSolve. Тогда альтернативный алгоритм с предварительным
вычислением матрицы перехода, реализующий метод Рунге–Кутта, будет обозначен через RKTransMatrix.
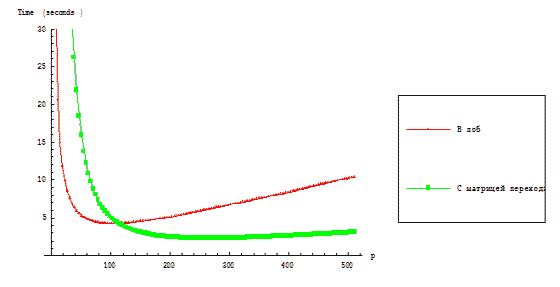
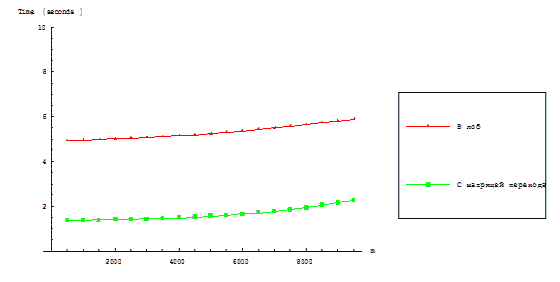
На рисунках 3.1 и 3.2 представлены функции времени выполнения параллельных алгоритмов RKStepSolve
и RKTransMatrix.
Рисунок 3.1 – Зависимость времени выполнения параллельных алгоритмов решения от размерности
вычислительной решётки при фиксированной размерности задачи
На рисунке 3.1 приведена зависимость времени выполнения параллельных реализаций алгоритмов
RKStepSolve и RKTransMatrix от величины размерности решётки–тора при фиксированной размерности
матриц и векторов.
Рисунок 3.2 – Зависимость времени выполнения параллельных алгоритмов решения от размерности задачи
при фиксированной размерности вычислительной решётки
Рисунок 3.2 отражает зависимость времени выполнения параллельных алгоритмов–реализаций RKStepSolve
и RKTransMatrix метода Рунге–Кутта от размерности матриц и векторов при фиксированном числе процессоров
в измерении решётки–тора.
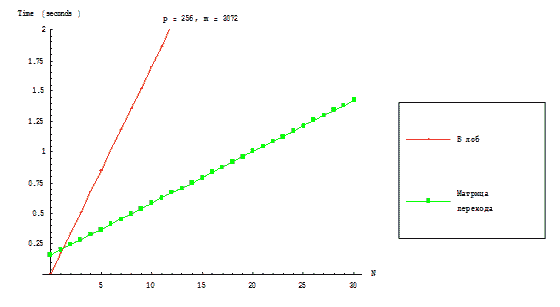
Рисунок 3.3 отражает зависимость времени выполнения параллельных алгоритмов–реализаций RKStepSolve
и RKTransMatrix метода Рунге–Кутта при фиксированных размерностях решётки–тора и сложности исходной
задачи.
Рисунок 3.3 – Зависимость времени выполнения параллельных алгоритмов решения от числа шагов метода
Рунге–Кутта при фиксированных величинах размерности вычислительной решётки и сложности исходной
задачи
|