6 Математический аппарат, используемый в магистерской работе
Для решения поставленной задачи – прогнозирования степени риска развития ишемического инсульта- в качестве математического аппарата можно использовать как нейронные сети, так и генетическое программирование.
Однако использование нейронных сетей обладает определенным недостатком. Работая по принципу «черного ящика», можно задать значения на входе и получить конечные результаты, не имея при этом возможности наблюдать за процессом принятия именно этого решения. Таких недостатков лишено генетическое программирование.
Генетическое программирование (genetic programming, GP) — одна из самых удобных и универсальных методик решения задач, встающих перед разработчиками. Оно применяется для решения широкого круга проблем: символьной регрессии, анализа данных (data mining), оптимизации и исследования поведения появляющегося потомства в биологических сообществах.[7]
Генетическое программирование относится к классу технологий, называемых эволюционными алгоритмами. Эволюционные алгоритмы основаны на понятиях, используемых при изучении естественного отбора и эволюции. Генетическое программирование использует дарвинистский принцип естественного отбора. Генетическое программирование - это процедуры поиска, основанные на механизмах естественного отбора и наследования. В них используется эволюционный принцип выживания наиболее приспособленных особей.
Генетическое программирование представляет собой модификацию генетического алгоритма с учетом возможностей компьютерных программ.
При использовании генетического программирования популяция состоит из закодированных соответствующим образом программ, которые подвергаются воздействию генетических операторов для нахождения оптимального решения, которым считается программа, наилучшим образом решающая поставленную задачу. Программы оцениваются относительно определенной специальным образом функции приспособленности.
Компьютерные программы в генетическом программировании могут представляться как деревья, и производство последующих поколений достигается применением генетических операторов – скрещивания (кроссинговера), репродукции и мутации.[8, 9]

Анимация - Основные генетические операторы (кадров 31, циклов 10)
Оператор мутации играет второстепенную роль по сравнению с оператором скрещивания. Это означает, что скрещивание в классическом генетическом алгоритме производится практически всегда, тогда как мутация -достаточно редко. Вероятность скрещивания, как правило, достаточно велика (обычно 0,5 < рс < 1), тогда как вероятность мутации устанавливается весьма малой (чаще всего 0 < рт < 0,1). Это следует из аналогии с миром живых организмов, где мутации происходят чрезвычайно редко.[3]
В генетическом программировании мутация хромосом может выполняться на популяции родителей перед скрещиванием либо на популяции потомков, образованных в результате скрещивания.
Чтобы избежать потери сформировавшихся «ценных особей» и улучшить сходимость алгоритма, применяется репродукция, т. е. копирование удачных программ целиком в последующее поколение.
В генетическом программировании особи из популяции представляют собой программы, которые удобно представлять в виде деревьев, где функции- внутренниме узлы, к которым в качестве входных параметров присоединены поддеревья. При этом кроссинговер будет заключаться в подмене одного из поддеревьев первого родителя на какое-либо поддерево второго родителя. Мутация будет выполнять случайное изменение одного из узлов дерева.
Начальная популяция генерируется беспорядочно как отправная точка для процесса. Новая популяция генерируется от предыдущего поколения, используя генетические операторы. Вероятность того, что данная особь будет участвовать в генерации для нового поколения, увеличивается соответственно функции приспособленности. Оценка приспособленности и развития повторяется неоднократно, пока решение не будет найдено, или время ожидания не истечет. Таким образом, основные шаги ГП следующие:
а) инициализация, или выбор исходной популяции хромосом;
б) оценка приспособленности хромосом в популяции;
в) проверка условия остановки алгоритма;
г) селекция хромосом;
д) применение генетических операторов;
е) формирование новой популяции;
ж) выбор «наилучшей» хромосомы.
Алгоритм ГП приведен на рисунке 2.
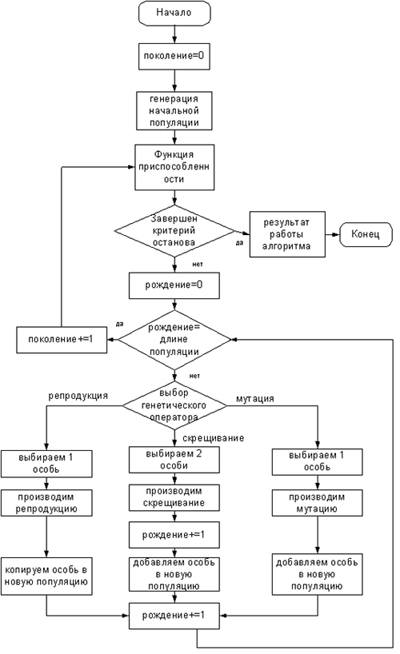
Рисунок 2 - Алгоритм ГП
Первый главный шаг в подготовке использования генетического программирования должен идентифицировать множество терминалов. Набор терминалов, наряду с набором функций, представляет собой компоненты, из которых будет создаваться компьютерная программа для полного или частичного решения проблемы.
Второй шаг заключается в определении функционального множества, элементы которого должны использоваться для генерации математических выражений. Каждая компьютерная программа (то есть, анализируемое дерево, математическое выражение) является композицией функций от множества функций F и терминалов из терминального множества T (в случае программ-функций это константы и переменные).
Множество возможных внутренних узлов (не листовых), используемых в деревьях синтаксического анализа, используемых в генетическом программировании, называется функциональным множеством.[10]
Каждая функция из функционального множества характеризуется арностью - количеством входящих параметров.
Множество листовых узлов в деревьях синтаксического анализа, представляющих программы в генетическом программировании, называются терминальным множеством.
Функциональное и терминальное множества могут быть объединены в однородную группу С, при условии, что терминалы рассматриваются как функции с нулевой арностью.
Пространством поиска генетического программирования является множество всех возможных рекурсивных композиций функций множества C.
В функциональном множестве могут быть применены арифметические, математические, булевы и другие функции. В терминальное множество могут войти переменные, константы или директивные команды.
Программы, как уже отмечалось, оцениваются относительно определенной специальным образом функции приспособленности. Чем больше значение этой функции, тем выше «качество» программы. Форма функции приспособленности зависит от характера решаемой задачи. Предполагается, что функция приспособленности всегда принимает неотрицательные значения и, кроме того, что для решения оптимизационной задачи требуется максимизировать эту функцию.
Определение условия остановки генетического алгоритма зависит от его конкретного применения. В оптимизационных задачах, если известно максимальное (или минимальное) значение функции приспособленности, то остановка алгоритма может произойти после достижения ожидаемого оптимального значения, возможно - с заданной точностью. Остановка алгоритма также может произойти, когда его выполнение не приводит к улучшению уже достигнутого значения или произошло истечение определенного времени выполнения либо после выполнения заданного количества итераций. Если условие остановки выполнено, то производится переход к завершающему этапу выбора «наилучшей» особи.
|