
Системы искусственного интеллекта
Целью работы является повышение качества поиска информации в Web путем применения модификации метода тематически-ориентированной классификации текстовых документов.
Развитие сетевых технологий привело к значительному увеличению числа доступных информационных ресурсов и объемов передаваемой информации. Необходимость эффективного использования этого огромного и динамично изменяющегося объема информации обуславливает актуальность и значимость исследований в области информационного поиска. Согласно опросу пользователей Интернет более 63% от общего числа пользователей используют системы поиска в World Wide Web практически каждый день [1].
В области информационного поиска отдельно выделяется задача тематического поиска, то есть целенаправленного поиска документов, относящихся с той или иной степенью релевантности к определенной теме, заявленной пользователем. При проведении исследований, обучении и профессиональной деятельности, в связи с высокой скоростью появления новой информации возникает потребность не только в нахождении сведений, соответствующих одной или нескольким темам, но и в постоянном получении новых данных. Одним из возможных вариантов удовлетворения этой потребности является периодическое обновление ранее полученных сведений, по аналогии с подпиской на тематические издания, такие как специализированные газеты и журналы. Для обеспечения такого рода доставки информации из Web необходимо решить задачу периодического тематического поиска, то есть такого поиска, который ведется систематически, через определенные промежутки времени. Причем ищутся не только обновления на уже известных Web-сайтах, но и новые сайты [2].
К недостаткам методов поиска, использующих запросы по ключевым словам, относят слабую выразительность языка запросов и высокую трудоемкость составления оптимального запроса, что приводит к низкому качеству тематического поиска в Web [3]. С другой стороны, существует множество успешно применяемых методов определения тематической принадлежности документов, в том числе и с использованием алгоритмов классификации, использующих обучающие коллекции документов. Однако высокая вычислительная сложность задач обучения и классификации ограничивает практическую применимость таких методов для Web [4].
В этих условиях разработка метода тематического поиска в Web в условиях долговременности информационной потребности пользователя и динамичности пространства поиска, повышающего качество поиска по сравнению с традиционными методами, представляется актуальной.
В работе предложен эффективный метод и алгоритмы решения задачи тематического поиска в Web, отличающиеся от существующих комбинацией поиска по ключевым словам и тематической фильтрации на основе классификаторов текстов для ограниченных по объему коллекций документов.
На базе разработанных алгоритмов могут быть реализованы программные средства для создания и обновления тематических коллекций документов для систем компьютерного обучения и информационного обеспечения научных исследований.
Методы классификации текстов лежат на стыке двух областей - машинного обучения (machine learning, ML) и информационного поиска (information retrieval, IR) [5, 6]. Соответственно автоматическая классификация может осуществляться:
Разработке методов классификации текстов и связанным с ними алгоритмам представления текстов посвящены труды таких авторов как Krishnapuram R., Keller J., Zhang C., D.D. Lewis, R.E. Schapire, H. Schutze, F. Sebastiani, Y. Yang, S.T. Dumais М. С., Агеев, И. Е. Кураленок, И. С. Некрестьянов.
В статье [7] исследуются различные методы усечения пространства признаков, и производится сравнение методов машинного обучения на задаче классификации текстов коллекции Reuters. Сравниваются следующие методы: FindSimilar (аналог k-ближайших соседей), метод Байеса, Байесовы сети, деревья решений, SVM. Как утверждают авторы метод SVM имеет преимущество над другими исследуемыми методами машинного обучения.
В работе [8] предложен метод автоматической классификации документов по множеству заданных тематик. Метод использует латентно-семантический анализ для извлечения семантических взаимосвязей между словами. Относительно низкая вычислительная трудоемкость метода делает возможным его применение для классификации документов, поступающих в систему динамически.
В статье [9] представлены результаты исследований проблемы автоматической классификации документов как одного из аспектов систем управления знаниями, областью применения которых может рассматриваться задача поддержки инновационной деятельности. В качестве инструмента для решения этой задачи предлагается разрабатываемая надстройка над полнотекстовыми базами знаний, включаемыми в состав интеллектуальных информационных систем, обеспечивающая автоматическую классификацию документов и представляющая извлеченные из документов знания в виде, эффективном для проведения анализа технических систем.
В работе [10] для того чтобы повысить релевантность поиска информации в Интернете, предлагается использовать знания пользователя о Предметной Области, которая его интересует, представленные в виде онтологии. На основе множества терминов онтологии Предметной Области строится тезаурус пользователя, который используется для оценки того, насколько интересен этот ИР пользователю.
В работе [11] рассмотрен подход к решению задачи Text Mining по извлечению информации об объектах из текстовых документов и переносу в базу данных для последующего извлечения знаний на основе стандартных методов Data Mining. Сформулированы требования к системе извлечения и структурирования данных. Предложена структурная организация системы и выбраны алгоритмы извлечения.
Автором работы [12] рассмотрена методика измерения характеристик классификатора и выбраны метрики для повышения эффективности классификации. Разработана модель представления документов с учетом гиперссылок и алгоритмы политематической классификации на основе бинарного метода и ранжирования.
В настоящее время в Internet представлены два основных вида служб поиска информации: тематические каталоги ресурсов и машины поиска (МП). Эти универсальные средства обладают целым рядом недостатков с точки зрения поиска научной информации.
Процесс отнесения документа к одному из разделов тематического каталога не поддается полностью автоматизации, поэтому каталоги охватывают ограниченное количество ресурсов и не успевают
за ростом сети.
Машины поиска в настоящее время реализуют два вида поиска: традиционный поиск по ключевым словам и относительно новый – семантический поиск.
Машины поиска по ключевым словам охватывают больше ресурсов и чаще обновляются. Однако нередко они оказываются малоэффективными с точки зрения поиска научной информации из-за большого уровня шума (ссылок на нерелевантные документы), ограниченных возможностей языков запросов и формы представления результатов поиска.
Технологии семантического интернет-поиска отличаются от традиционного поиска по ключевым словам тем, что позволяют поисковой системе считывать запрос пользователя на естественном языке и давать прямой ответ на поставленный вопрос. Такой вид поиска не оправдывает себя при поиске тематической информации в отдельной или нескольких предметных областях.
Для повышения релевантности поиска по ключевым словам используются различные методы, которые можно разделить на два основных класса.
В первом классе методов производится уточнение и расширение поискового запроса для повышения релевантности выдачи поискового сервиса либо автоматически, либо с участием пользователя. Методы решения этой задачи разделяются на глобальные и локальные. Глобальные методы предусматривают расширение или новую формулировку запроса независимо от запроса и возвращаемых результатов, так что изменения в формулировке запроса приводят к появлению нового запроса, соответствующего другим семантически близким терминам.
К глобальным относятся следующие методы:
Локальные методы изменяют запрос с учетом документов, найденных по исходному запросу. К локальным относятся следующие методы:
Во втором классе используется две группы методов: классификация веб-страниц на основе алгоритмов машинного обучения с использованием универсальных классификаторов и методы назначения определенных категорий или тематик документам и результатам поиска для улучшения их презентации. В первой группе методов проблемой являются большие вычислительны затраты на классификацию, сложность построения универсальных классификаторов и большие объемы данных в веб [13].
Во второй группе методов применяются механизмы, использующие кластерный анализ (data clustering, кластеризация), которые обеспечивают лучшую презентацию результатов поиска, потому что организуют их в структуру. Этот метод заключается в назначении определенных категорий или тематик документам и результатам поиска. Понятие кластер означает множество, совокупность, связку или просто группу. Кластеризация направлена на сортировку результатов поиска в одну или несколько таких групп, и таким образом извлекает группы из всех результатов. Условием успеха является предварительное определение групп, а также категорий, тематик или слоев, которые, в свою очередь, определяются ключевыми словами и профессиональными понятиями. Для того, чтобы документ мог быть назначен группе, он должен быть правильно классифицирован. Реализация этого намерения не всегда оказывается достаточно простой. Чтобы ее сделать, поисковая система читает, после чего исследует данные и метаданные документа. Также анализирует содержание документа на основе статистических расчетов (принимает во внимание частоту появления букв, слогов и слов, порядок фраз, а также длины слов и предложений), или использует алгоритмы лингвистического анализа. Чем более точны эти данные, тем точнее можно выделить документ в определенной группе [14].
Проведенный анализ существующих подходов показывает, что в случае, когда релевантные результаты поиска по заданной теме могут предоставляться не сразу, а через определенные промежутки времени, целесообразно сочетать поиск по ключевым словам с последующей классификацией результатов выдачи поисковых серверов. В этом случае снимаются жесткие ограничения на вычислительную сложность алгоритмов классификации и уменьшается объем классифицируемых документов. Такой подход планируется реализовать в данной работе.
В научной деятельности, обучении и других сферах существует необходимость в постоянном поиске публикаций по ряду тематик. Для решения этой задачи в работе предлагается метод тематического поиска в Web, основанный на комбинации поиска по ключевым словам и тематической фильтрации с использованием классификаторов текстов, применяемой в ограниченных по объему коллекциях документов. Отбор документов при помощи поиска по ключевым словам позволяет значительно сократить множество анализируемых классификатором документов, что приводит к уменьшению вычислительной сложности метода в целом по сравнению с методом тематической фильтрации и, как следствие, применимости полученного метода на больших объемах данных, характерных для Web.
Информационная потребность пользователя представляется в виде пары {q, D}, где q – запрос по ключевым словам (запрос по КС), использующийся для первичного отбора документов из Web, D = {D+, D-} – обучающая выборка, описывающая тему, интересующую пользователя. Данная обучающая выборка содержит примеры релевантных теме документов (D+) и нерелевантных документов (D-).
Процесс поиска разделяется на два этапа:
Для реализации классификации результатов поиска пользователю необходимо в обучающей выборке множество релевантных документов D+ разбить на подмножества, описывающие интересующие пользователя подтемы. В этом случае обучающая выборка будет представлять собой множество
D={D1+, D2+, D3+,…, Dn+, D-},
где Di+ - обучающая выборка i-ой подтемы, n – общее количество подтем.
Таким образом, в этом случае классификатор будет решать две задачи: задачу тематической фильтрации (бинарной классификации) и задачу разбиения множества релевантных теме документов на подтемы (задачу классификации с большим количеством классов в обучающей выборке). Общий вид технологии тематического поиск на основе предлагаемого метода представлен на рис. 1.

Рис. 1. Основные этапы тематического поиска
(анимация: 8 кадров, 10 циклов повторений, 113Kb)
Рассмотрим более детально второй этап метода - задачу уточнения результатов поиска.
Формальная постановка задачи классификации текстов выглядит следующим образом.
Предполагается, что алгоритм классификации работает на некотором множестве документов
D={di}.
Все множество документов разбивается на непересекающиеся подмножества классов
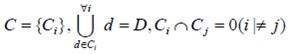
Задачей классификации является определение класса, к которому относится данный документ.
Анализ публикаций по сравнению существующих методов подтверждают преимущество алгоритма классификации по методу опорных векторов – SVM [6] над другими алгоритмами. Для решения задачи классификации результатов поиска данный алгоритм не применим из-за низкой скорости обучения (O(|D|a, где a>1,2 [5])) и больших затрат памяти. Однако его можно использовать в качестве эталона при сравнении алгоритмов классификации.
Исходя из сказанного, требования к алгоритму классификации для решаемой задачи формулируются следующим образом:
Для обеспечения масштабируемости и приемлемой вычислительной сложности можно использовать в качестве базовых алгоритмы Байеса и разделяющих гиперплоскостей с линейной (O(N)) сложностью обучения.
Метод Байеса это простой классификатор, основанный на вероятностной модели, имеющей сильное предположение независимости компонент вектора признаков [9]. Обычно это допущение не соответствует действительности и потому одно из названий метода - Naive Bayes (Наивный Байес). Простой байесовский классификатор относит объект X к классу Ci тогда и только тогда, когда выполняется условие:
P(Ci|X)>P(Cj|X),
где P(Ci|X) – апостериорная вероятность принадлежности объекта X к классу Ci, P(Cj|X) – апостериорная вероятность принадлежности объекта X к произвольному классу Cj, отличному от Ci.
Иными словами, апостериорная вероятность принадлежности объекта к классу Ci больше апостериорной вероятности принадлежности объекта к любому другому классу.
Алгоритм Байеса в настоящее время оценивается как сравнительно низкокачественный алгоритм. Основными причинами являются проблемы, связанные с принципом независимости признаков и некорректной оценкой априорной вероятности в случае существенно неравномощных обучающих выборок.
Правило определения класса для документа в алгоритме Байеса можно представить следующим образом:
 ,
,
где fw - количество вхождений признака w в документ,

Для борьбы с некорректным определением априорной условной вероятности признаков в случае неравномощных обучающих выборок, используется парадигма класса-дополнения, то есть вместо вероятности принадлежности лексемы классу оценивается вероятность принадлежности лексемы классу-дополнению C’ (следует учесть, что p(w|C) ~ 1-p(w|C’)). Используя принцип сглаживания параметров по Лапласу, получаем следующее правило:
 ,
,
где NCw - количество вхождений признака во все классы кроме данного, NC - общее количество вхождений всех признаков в класс-дополнение, |V| - размерность словаря признаков.
Следует отметить, что данная эвристика работает только в том случае, если количество классов |С| >> 2.
Для частичной компенсации использования принципа независимости признаков, производится нормализация весов признаков:
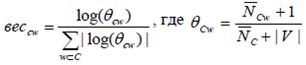
Для задачи бинарной классификации рассмотренные модификации не позволяют приблизить метод Байеса по качеству к лучшим показателям (парадигма классов-дополнений не вносит никаких изменений), поэтому для данного случая предлагается использовать алгоритм, основанный на линейном дискриминанте Фишера. В основе алгоритма лежит поиск в многомерном признаковом пространстве такого направления w, чтобы средние значения проекции на него объектов обучающей выборки из классов максимально различались. На рис. 2 показан выбор двух различных значений w для двумерного случая. Мерой разделения спроецированных точек служит разность средних значений выборки. Желательно, чтобы проекции на прямой были хорошо разделены и не очень перемешаны.
Проекцией произвольного вектора X на направление w является отношение 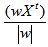 . В качестве меры различий проекций классов на w используется функционал – индекс Фишера:
. В качестве меры различий проекций классов на w используется функционал – индекс Фишера:
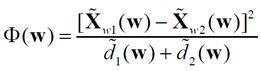 , (1)
, (1)
где 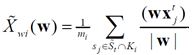 - среднее значение проекции векторов, описывающих объекты из класса
- среднее значение проекции векторов, описывающих объекты из класса  ,
,  - выборочная дисперсия проекций векторов, описывающих объекты из класса.
- выборочная дисперсия проекций векторов, описывающих объекты из класса.
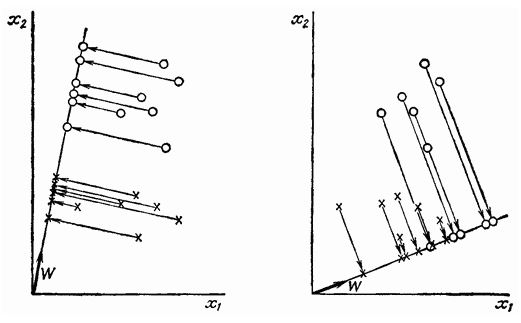
Рис. 2. Проекция выборок на прямую
Линейный дискриминант Фишера определяется как линейная разделяющая функция wtx , максимизирующая функционал (1).
Для более полного разделения классов в алгоритме строится несколько направлений соответствующих дискриминанту Фишера. Вдоль одного направления можно эффективно разделить часть обучающих экземпляров. Точки отсечения для положительных и отрицательных экземпляров вдоль каждого направления запоминаются при обучении алгоритма.
Схема обучения алгоритма представлена на рис. 3.
Классификация экземпляра производится по следующему алгоритму:
цикл i = 1... L (количество направлений)
Анализируем i-oe направление:
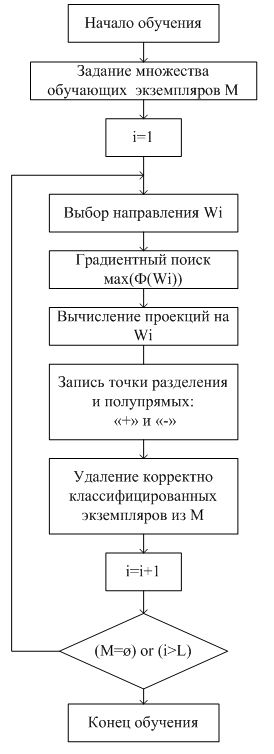
Рис. 3. Блок-схема обучения алгоритма бинарной классификации
Задачей этапа предварительной обработки документов является выделение признаков документа и сопоставления им весов.
В простейшем случае набором признаков документа будет содержащийся в нем набор лексем, а в качестве веса используется количество вхождений лексемы в документ. Недостатком такого подхода является то, что практически не учитываются особенности естественного языка, а также структурированность документа и связи между документами в случае Web-страниц. При обработке Web-страниц необходимо предусмотреть автоматическое определение кодировки, поскольку явно она указывается не во всех документах. Для решения этой задачи производится анализ частоты вхождения наиболее часто используемых литер или, в случае когда частотный анализ не позволяет сделать определенный вывода, производится проверка наличия части выделенных лексем в морфологическом словаре. В случае, если частотный или словарный анализ показали несоответствие кодировки, текст документа конвертируется в другую кодировку.
При обработке документа производится увеличение веса лексем, входящих в заголовки, названия, ключевые слова, текст ссылки и т.п.
В дальнейшем предполагается усовершенствование подготовки документов к применению методов машинного обучения путем выбора более эффективной формы оценки весов признаков документа, учитывающей ссылки. Проведение экспериментов по усовершенствованию байесовского классификатора документов для тем с большим количеством неравномощных подтем. Разработка критериев оценки качества поиска с применением предложенных алгоритмов.
Проведен анализ существующих подходов к повышению релевантности тематического поиска путем классификации результатов выдачи поисковых систем. Разработаны алгоритмы фильтрации и классификации с малой вычислительной сложностью. Классификация результатов поиска позволяет существенно сократить время поиска нужной информации. Таким образом, введение дополнительной классификации на получаемые пользователем документы позволяет повысить удобство использования поисковой системы и позволяет быстрее ориентироваться в полученных результатах.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.