
Введение
Преобразование Фурье используется во многих областях науки – в физике, теории чисел, комбинаторике, обработке сигналов, теории вероятности, статистике, криптографии, акустике, океанологии, оптике, геометрии, и многих других. При обработке сигналов различной природы преобразование Фурье обычно рассматривается как трансформация сигнала из временной области в частотную.
Дискретное преобразование Фурье играет важную роль при анализе, синтезе и разработке систем и алгоритмов цифровой обработки сигналов. Одна из причин того, что анализ Фурье играет такую важную роль в цифровой обработке сигналов, заключается в существовании эффективных алгоритмов дискретного преобразования Фурье.
Преобразования обратимы, причем обратное преобразование имеет практически такую же форму, как и прямое преобразование.
Быстрое преобразование Фурье применяется во многих областях: радиолокации, сжатии видео и изображений, геологии. Многие из данных задач требуют выполнения преобразований в реальном времени, с минимальной временной задержкой вычислений.
Для уменьшения времени, необходимого для выполнения преобразований, возможно распараллеливания задачи, выполнение ее на параллельной вычислительной системе.
Цель данной исследовательской работы – изучение алгоритмов быстрого преобразования Фурье двумерных сигналов, дальнейшая разработка программного обеспечения работающего на параллельной вычислительной системе, выполняющего вычисления в реальном времени.
Задачи данной работы:
- изучение различных алгоритмов дискретного двумерного быстрого преобразования Фурье;
- изучение существующих параллельных вычислительных систем;
- проектирование и написание программных продуктов, выполняющих быстрые преобразования Фурье для больших изображений в реальном времени.
Актуальность
В данное время над этой проблемой работают многие ученые, такие как Брандон Блойд, Юрий Доценко, Бартон Смит, Джон Манферделли и другие. Данная тема актуальна, в связи с широким применением преобразований Фурье в различных сферах науки. С развитием компьютерной техники у данной задачи возникает все больше и больше эффективных вариантов реализации на практике.
Новизна
В настоящее время существует много методов и алгоритмов БПФ, которые реализованы как в виде специальных пакетов, так и в таких стандартных мощных математических пакетах, как Matlab, Mathcad и Mathematica.
Но при достаточно больших объемах вычислений они могут и не предоставлять необходимой скорости выполнения преобразований, хотя и являются идеальным средством проверки правильности полученных результатов.
Новизна данной работы заключается в реализации дискретного двумерного быстрого преобразования Фурье для больших изображений в реальном времени, ориентируясь на то, чтобы полученные результаты можно было использовать для дальнейшей обработки, без ощутимой временной задержки.
Планируемые практические результаты
В результате выполнения работы, планируется получить программный продукт, позволяющий выполнять двумерные быстрые преобразования Фурье для изображений больших размеров, таких как фотографии со спутника (100000 на 100000 пикселей) в реальном времени.
Есть два подхода к решения данной проблемы – поиск наилучших алгоритмов, улучшающих быстродействие системы, уменьшающих количество выполняемых операций, и использование специальной аппаратуры, с большими вычислительными возможностями, такой как параллельная вычислительная система.
Существует большое количество эффективных алгоритмов быстрого преобразования Фурье, и выбор наиболее оптимального из них зависит от аппаратных средств.
Среди существующих параллельных вычислительных систем следует выделить кластер, и графические процессоры. Планируется определение эффективности для решения данной задачи на каждой из этих систем. Но следует отметить, что кластер является значительно более дорогостоящей системой, чем графический процессор (в данной работе рассматриваются графические процессоры NVIDIA с поддержкой технологии CUDA), и при не значительной разнице во времени вычислений и ограниченных материальных средствах более приемлемым будет выбор второй параллельной вычислительной системы.
Практическое решение задачи состоит в нахождения золотой середины между этими подходами, позволяющей при эффективном алгоритме решения задачи и соответствующих аппаратных средствах получить оптимальные практические результаты.
Обзор исследований
В мире уже существует большое количество разработок связанных с алгоритмами БПФ, реализованных на различных архитектурах. Среди них можно выделить такие архитектуры:
- кластер;
- графические процессоры;
- Cell процессоры.
Среди огромного количества исследований следует особо отметить разработки сотрудников корпорации Microsoft Нага К. Говидараю, Брандона Ллойда, Юрия Доценко, Бартона Смита, и Джона Манферделли, а так же Василия Волкова. В своей статье «Высокопроизводительные дискретные преобразования Фурье на графических процессорах»[1] они привели следующий анализ существующих мировых исследований в области быстрых преобразований Фурье и параллельных вычислительных систем:
«Соренсен и Баррус скомпилировали базу данных с более 34000 алгоритмами эффективных БПФ[2]. Книга Ван Лоана[3] обеспечивает понимание многих вариаций БПФ с помощью матричной структуры. Книга так же рассматриваем многие из важных проблем реализации. Исследования, ближе всего связанные с темой данной работы предполагают ускорение вычисления БПФ, используя соответствующую аппаратуру, такую как графические или Cell процессоры. Большинство реализаций БПФ на графических процессорах используют графическое API, такое как текущая версия OpenGL или DirectX[4],[5][6],[7],[8],[9]. Тем не менее, это API не поддерживает прямо рассеивания, доступ в разделяемую память, или хорошо раздробленную синхронизацию, доступную на современных графических процессорах. Доступ к этим характеристикам в данный момент предоставляется только специфическими API. Библиотека компании NVIDIA для вычисления БПФ CUFFT[10], использует CUDA API[11] для достижения более высокой производительности, чем это возможно с графическими API. Конкурирующая работа Волкова и Казиана[12] так же обсуждает применение CUDA. Несколько разработок рассматривают применение БПФ на процессорах Cell [13],[14],[15],[16],[17]».[1]
Так же Василий Волков разработал и реализовал алгоритм быстрого преобразования Фурье, использующийся в стандартной библиотеке NVIDIA CUFFT, а так же представил его усовершенствованный вариант.
В Украине исследованием данной темы занимались:
- кандидат технических наук Троянский А.В. в диссертации «Поточные процессоры быстрого преобразования Фурье с перестраиваемой архитектурой на однотипных СБИС»[18];
- кандидат технических наук Гюрджян М.К. в диссертации по теме «Некоторые вопросы организации параллельных вычислений в многопроцессорных вычислительных системах кластерного типа»[19];
- кандидат технических наук Потопальский В.В. в работе «Оценка качества преобразования Фурье в радиотехнических и телевизионных системах»[20];
- кандидат технических наук Керекеша П.В. в диссертации по теме «Комбинированный метод преобразования Фурье и сопряжения аналитических функций в задачах теории упругости»[21].
Среди преподавателей и студентов Донецкого национального технического университета похожие задачи исследует моя однокурсница Смоляная Д.В. в магистерской работе «Исследование эффективности параллельной реализации быстрого преобразования Фурье для цифровых изображений».
Тема быстрых преобразований Фурье затронута так же и в следующих работах:
- магистр Алтухов С.В. «Методы преобразования сигналов входными цепями системы виброакустической диагностики»;
- магистр Синельников В.Б. «Разработка и исследование метода оценивания текущих спектров радиочастотных сигналов применительно к задаче восстановления их информационных параметров»;
- магистр Хоменко В.Н. «Разработка типовых моделей электромеханических систем для анализа возможных аварийных ситуаций в узлах производственных механизмов»;
- магистр Горелкин А.В. «Исследование и обоснование структуры и параметров микропроцессорного устройства контроля вибрации шахтных насосных установок»;
- магистр Нафтулин И.В. «Спектральный анализ токов статора асинхронных двигателей с короткозамкнутым ротором»;
- магистр Выростков М.А. Исследование и разработка алгоритмов и микропроцессорных структур цифровой обработки сигналов от шахтной системы сигнализации концентрации метана»;
- магистр Коков А.А. аспирант Меркулова Е.В. «Автоматизированная подсистема распознавания оконтуривания клеток».
Преобразование Фурье
Преобразование Фурье — операция, сопоставляющая функции вещественной переменной другую функцию вещественной переменной. Эта новая функция описывает коэффициенты (амплитуды и фазы) при разложении исходной функции на элементарные составляющие – гармонические колебания с разными частотами.
Дискретное преобразование Фурье
Дискретным преобразованием Фурье (ДПФ) над исходной последовательностью чисел
{x0, x1, …, xn-1},
мощностью n є N, n>1, где xi є Z, i = (0, n-1), называется такое преобразование, в результате которого получается последовательность
{x-0, x-1, …, x-n-1}
комплексных чисел Xk той же мощности, каждый элемент которой рассчитывается по следующему правилу:
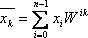
Рисунок 1 - Формула для вычисления ДПФ
где k = (0, n-1), W = e^(-j*Pi/n), где j – мнимая единица.[22]
Быстрые преобразования Фурье
Алгоритм быстрого преобразования Фурье (БПФ) - это оптимизированный по скорости способ вычисления ДПФ. Основная идея заключается в следующем:
- Необходимо разделить сумму (см. рис.1) из N слагаемых на две суммы по N/2 слагаемых, и вычислить их по отдельности. Для вычисления каждой из подсумм, надо их тоже разделить на две и т.д.;
- Необходимо повторно использовать уже вычисленные слагаемые.
Применяют либо «прореживание по времени» (когда в первую сумму попадают слагаемые с четными номерами, а во вторую - с нечетными), либо «прореживание по частоте» (когда в первую сумму попадают первые N/2 слагаемых, а во вторую - остальные). Оба варианта равноценны. В силу специфики алгоритма приходится применять только N, являющиеся степенями 2. В данной работе рассмотрен случай с прореживанием по времени.
В основе алгоритма БПФ лежат следующие формулы:

Рисунок 2 - Формулы алгоритма БПФ
Теперь рассмотрим конкретную реализацию БПФ. Пусть имеется N=2^T элементов последовательности x{N} и надо получить последовательность X{N}. Прежде всего, нам придется разделить x{N} на две последовательности: четные и нечетные элементы. Затем точно так же поступить с каждой последовательностью. Этот итерационный процесс закончится, когда останутся последовательности длиной по 2 элемента. Пример процесса для N=16 показан на рисунке 3.
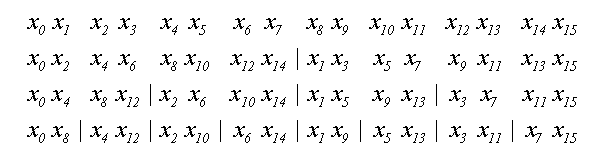
Рисунок 3 – Перестановка элементов множества x
Итого выполняется (log2(N))-1 итераций.
Рассмотрим двоичное представление номеров элементов и занимаемых ими мест. Элемент с номером 0 (двоичное 0000) после всех перестановок занимает позицию 0 (0000), элемент 8 (1000) - позицию 1 (0001), элемент 4 (0100) - позицию 2 (0010), элемент 12 (1100) - позицию 3 (0011). И так далее. Нетрудно заметить связь между двоичным представлением позиции до перестановок и после всех перестановок: они зеркально симметричны. Двоичное представление конечной позиции получается из двоичного представления начальной позиции перестановкой битов в обратном порядке. И наоборот[22].
Этот факт не является случайностью для конкретного N=16, а является закономерностью. На первом шаге четные элементы с номером n переместились в позицию n/2, а нечетные из позиции в позицию N/2+(n-1)/2. Где n=0,1,…,N-1.
На рисунке 4 проиллюстрирован второй этап вычисления ДПФ

Рисунок 4 – Второй шаг ДПФ
(5 кадров, 276х204 пикселей, 10 повторений, задержка 1c)
Линиями сверху вниз показано использование элементов для вычисления значений новых элементов. Очень удобно то, что два элемента на определенных позициях в массиве дают два элемента на тех же местах. Только принадлежать они будут уже другим, более длинным массивам, размещенным на месте прежних, более коротких. Это позволяет обойтись одним массивом данных для исходных данных, результата и хранения промежуточных результатов для всех T итераций.[22]
Двумерное дискретное преобразование Фурье
Двумерное дискретное преобразование Фурье – это дискретное преобразование Фурье над матрицей, которое вычисляют по формуле:
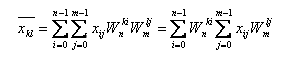
Рисунок 5 - Формула дискретного двумерного преобразования Фурье
где k, i = (0, n-1), l, j = (0, m-1), то есть это есть последовательное одномерное ДПФ сначала над строками, а потом над столбцами.[22]
Сущность технологии NVIDIA CUDA
CUDA (Compute Unified Device Architecture) - это технология от компании NVidia, предназначенная для разработки приложений для массивно-параллельных вычислительных устройств (в первую очередь для GPU начиная с серии G80).
Технология CUDA работает на видеокартах NVIDIA начиная с 8400GS и выше. Разные видеокарты имеют разные возможности. В целом, если в видеокарте например 128 SP(Streaming Processor) — это значит что там 8 SIMD MP (multiprocessor), каждый из которых делает одновременно 16 операций.
При использовании GPU разработчику доступно несколько видов памяти: регистры, локальная, глобальная, разделяемая, константная и текстурная память. Каждая из этих типов памяти имеет определенное назначение, которое обуславливается её техническими параметрами (скорость работы, уровень доступа на чтение и запись)[23]. Иерархия типов памяти представлена на рисунке 6.
 ,
,
Рисунок 6 - Типы памяти видеокарты
- Регистровая память (register) является самой быстрой из всех видов. Определить количество регистров доступных GPU можно с помощью уже функции cudaGetDeviceProperties. Рассчитать количество регистров, доступных одной нити GPU, так же не составляет труда, для этого необходимо разделить общее число регистров на произведение количества нитей в блоке и количества блоков в гриде. Все регистры GPU 32 разрядные. В CUDA нет явных способов использования регистровой памяти, всю работу по размещению данных в регистрах берет на себя компилятор;
- Локальная память (local memory) может быть использована компилятором при большом количестве локальных переменных в какой-либо функции. По скоростным характеристикам локальная память значительно медленнее, чем регистровая. В документации от nVidia рекомендуется использовать локальную память только в самых необходимых случаях. Явных средств, позволяющих блокировать использование локальной памяти, не предусмотрено, поэтому при падении производительности стоит тщательно проанализировать код и исключить лишние локальные переменные;
- Глобальная память (global memory) – самый медленный тип памяти, из доступных GPU. Глобальные переменные можно выделить с помощью спецификатора __global__, а так же динамически, с помощью функций из семейства cudMallocXXX. Глобальная память в основном служит для хранения больших объемов данных, поступивших на device с host’а, данное перемещение осуществляется с использованием функций cudaMemcpyXXX. В алгоритмах, требующих высокой производительности, количество операций с глобальной памятью необходимо свести к минимуму;
- Разделяемая память (shared memory) относиться к быстрому типу памяти. Разделяемую память рекомендуется использовать для минимизации обращение к глобальной памяти, а так же для хранения локальных переменных функций. Адресация разделяемой памяти между нитями потока одинакова в пределах одного блока, что может быть использовано для обмена данными между потоками в пределах одного блока. Для размещения данных в разделяемой памяти используется спецификатор __shared__;
- Константная память (constant memory) является достаточно быстрой из доступных GPU. Отличительной особенностью константной памяти является возможность записи данных с хоста, но при этом в пределах GPU возможно лишь чтение из этой памяти, что и обуславливает её название. Для размещения данных в константной памяти предусмотрен спецификатор __constant__. Если необходимо использовать массив в константной памяти, то его размер необходимо указать заранее, так как динамическое выделение в отличие от глобальной памяти в константной не поддерживается. Для записи с хоста в константную память используется функция cudaMemcpyToSymbol, и для копирования с device’а на хост cudaMemcpyFromSymbol, как видно этот подход несколько отличается от подхода при работе с глобальной памятью.
- Текстурная память (texture memory), как и следует из названия, предназначена главным образом для работы с текстурами. Текстурная память имеет специфические особенности в адресации, чтении и записи данных. Более подробно о текстурной памяти я расскажу при рассмотрении вопросов обработки изображений на GPU.
Основными плюсами CUDA являются ее бесплатность, простота (программирование ведется на «расширенном С») и гибкость.
Возможно улучшение производительности путем подключения сразу нескольких видеокарт.[24]
Если видеокарта подключена в монитору, то вычисления будут продолжаться только 5 секунд, а потом все значения сбрасываются. Решением данной проблемы является отключение драйвера, либо использование графического процессора только для вычислений.
Использование NVIDIA CUDA для вычисления быстрых преобразований Фурье
Для вычисления быстрых преобразований Фурье в технологии CUDA существует стандартная библиотека CUFFT. Недостатком этой библиотеки является ограничение на размер быстрого преобразования. Так же арифметика чисел с двойной точностью поддерживается только в последних версиях библиотеки.
CUDA вариант FFT поддерживает 1D, 2D, и 3D преобразования комплексных и действительных данных, пакетное исполнение для нескольких 1D трансформаций в параллели, размеры 2D и 3D трансформаций могут быть в пределах [2, 16384], для 1D поддерживается размер до 8 миллионов элементов.
Так же возможно уменьшение времени вычислений.
По этому, необходима разработка собственного алгоритма вычисления, эффективного для больших размеров преобразований, и поддерживающая арифметику чисел с двойной точностью.
Примеры алгоритмов вычисления и их результативность приведены в статье «Высокопроизводительные дискретные преобразования Фурье на графических процессорах».
Результаты
На данный момент, изучены основные алгоритмы вычисления дискретного двумерного быстрого преобразования Фурье. Так же рассмотрены уже существующие исследования по данной теме, изучены наиболее эффективные и полезные из них для дальнейшего развития и применения, особое внимание уделено алгоритмам распараллеливанием вычислений.
Была написана программа, вычисляющая двумерное быстрое преобразование Фурье для изображений. Время вычислений для входных данных разных размеров при тестировании программы на персональном компьютере приведены в таблице 1.
Таблица 1 - Время выполнения двумерного быстрого преобразования Фурье
| Высота | Ширина | Время выполнения |
| 4 | 4 | 0,0468 c |
| 8 | 8 | 0,0625 c |
| 16 | 16 | 0,0937 c |
| 64 | 64 | 0,3437 c |
| 512 | 512 | 5,5781 c |
| 1024 | 1024 | 26,8125 c |
| 2048 | 2048 | 1 мин 54,859 с |
Рассмотрена новая технология вычисления на графических процессорах NVIDIA CUDA. Изучены основные ее достоинства и недостатки. Так же скомпилирована и успешно выполнена тестовая программа на графическом процессоре NVIDIA GeForce 8600 GT.
Через месяц планируется написание программы, вычисляющей двумерное быстрое преобразование Фурье с использованием технологии NVIDIA Cuda.
Заключение
Рассмотренная архитектура и многообразие различных алгоритмов быстрого преобразования Фурье позволяют выполнять вычисления, значительно превосходящие возможности обычного персонального компьютера. Вычислительные возможности параллельных вычислительных систем позволяют получить планируемые результаты для выполнения дискретного двумерного быстрого преобразования Фурье в реальном времени для больших изображений.
При написании данного автореферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2009 г. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Литература
1. Говидараю Н.К., Ллойд Б., Доценко Ю., Смит Б., Манферделли Д. Высокопроизводительные дискретные преобразования Фурье на графических процессорах/ компания Microsoft, - ../library/translate.htm
2. Sorensen H.V., Burrus C. S. Fast Fourier Transform Database.PWS Publishing, 1995.
3. Loan C.V. Computational Frameworks for the Fast Fourier Transform / Society for Industrial Mathematics, 1992.
4. Moreland K., Angel E. The FFT on a GPU / Proceedings of the ACM SIGGRAPH/EUROGRAPHICS Conference on Graphics Hardware, 2003.
5. Spitzer J. Implementing a GPU-efficient FFT / SIGGRAPH Course on Interactive Geometric and Scientific Computations with Graphics Hardware, 2003.
6. Mitchell J.L., Ansari M.Y., Hart E. Advanced image processing with DirectX 9 pixel shaders / ShaderX2: Shader Programming Tips and Tricks with DirectX 9.0, W. Engel, Ed. Wordware Publishing, Inc.,2003.
7. Jansen T., B. Rymon-Lipinski B., Hanssen N., Keeve E. Fourier volume rendering on the GPU using a split-stream-FFT / Proceedings of the Vision, Modeling, and Visualization Conference 2004.
8. Sumanaweera T., Liu D. Medical image reconstruction with the FFT / GPU Gems 2, Pharr M., Ed. Addison-Wesley, 2005.
9. Govindaraju N.K, Larsen S., Gray J., Manocha D. A memory model for scientific algorithms on graphics processors / Supercomputing 2006.
10. CUDA CUFFT Library/ Официальный сайт разработчика, - http://developer.download.nvidia.com/compute/cuda/2_1/toolkit/docs/CUFFT_Library_2.1.pdf
11. NVIDIA CUDA: Compute Unified Device Architecture / NVIDIA Corp., 2007.
12. Volkov V., Kazian B. Fitting FFT onto the G80 architecture / компания Microsoft, - http:www.cs.berkeley.edu/kubitron/courses/cs258-S08/projects/reports/project6 report.pdf
13. Chow A.C., Fossum G.C, Brokenshire D.A. A programming example: Large FFT on the cell broadband engine / Whitepaper, 2005.
14. Cico L., Cooper R., Greene J. Performance and programmability of the IBM/Sony/Toshiba Cell broadband engine processor / Whitepaper, 2006.
15. Williams S., Shalf J., Oliker L., Kamil S., Husbands P., Yelick K. The potential of the cell processor for scientific computing / CF 06:Proceedings of the 3rd Conference on Computing Frontiers, 2006, pp.9–20.
16. Bader D.A., Agarwal V. FFTC: fastest Fourier transform for the IBM Cell broadband engine / 14th IEEE International Conference on High Performance Computing (HiPC), pp. 172–184, 2007.
17. Frigo M., Johnson S. G. FFTW on the cell processor / компания Microsoft, - http://www.fftw.org/cell/index.html
18. Троянский А.В. Поточные процессоры быстрого преобразования Фурье с перестраиваемой архитектурой на однотипных СБИС: Дис. канд. техн. наук: 05.12.21 / Одесский гос. политехнический ун-т. - О., 1997. - 185с. -
http://www.dissua.com/contua/pk-15757.html
19. Гюрджян М. К. Некоторые вопросы организации параллельных вычислений в многопроцессорных вычислительных системах кластерного типа: дис. канд. техн. наук: 05.13.05 / Институт проблем информатики и автоматизации НАН РА. - Ереван, 2004. -
http://www.dissua.com/contua/pk-20301.html
20. Потопальский В. В. Оценка качества преобразования Фурье в радиотехнических и телевизионных системах : дис.канд.техн.наук: 05.12.17 / АН Украины. — Львов, 1993. — 189с. -
http://www.dissua.com/contua/pk-260506.html
21. Керекеша П.В. Комбинированный метод преобразования Фурье и сопряжения аналитических функций в задачах теории упругости: Дис. д-ра физ.-мат. наук: 01.02.04 / Одесский гос. ун-т им. И.И.Мечникова. - О., 1999. - 314с. -
http://www.dissua.com/contua/pk-11181.html
22. Блейхут Р. Быстрые алгоритмы цифровой обработки сигналов. Москва, Мир – 1989. 248 с.
23. NVIdiA Cuda Programming Guide / сайт NVIDIA, - http://developer.download.nvidia.com/compute/cuda/2_2/toolkit/docs/NVIDIA_CUDA_Programming_Guide_2.2.pdf
24. Schivea H., Chiena C., Wonga S.,Tsaia Y., Chiueha T. Graphic-Card Cluster for Astrophysics (GraCCA) - Performance Tests / Сборник статей по математике, физике, программированию и др.,- http://xxx.lanl.gov/ftp/arxiv/papers/0707/0707.2991.pdf