
Abstract
Attention! This abstract refers to the unfinished work. Estimated completion date: June 2019. Contact the author after the specified date for the final version.
Content
- Introduction
- 1. Relevance of the topic
- 2. The purpose and objectives of the study
- 3. Review of research and development
- 3.1 Overview of international sources
- 3.2 Review of national sources
- 3.3 Local Source Overview
- 4. Recognition of text and selection of graphic material
- 4.1 Pre-processing the original image
- 4.2 Highlighting text and graphics
- 4.3 Text recognition
- 4.4 Summary Output
- Conclusions
- List of sources
Introduction
In the age of information technology and electronic signatures, ordinary paper documents have not lost their power. Workers in various fields of activity often have to manually type bulk texts due to the absence or inability to get electronic sources. The text itself can flow around various graphic material, which complicates this process. For its automation, there are printed text recognition systems. These systems come in the form of services and applications for different platforms (Windows, Android and others) [1].
1. Relevance of the topic
Now there are many systems for text recognition, but only a small part of them is able to select graphic material and transfer it to the final electronic document while preserving its position.
There are many methods for source image segmentation. Each is effective in different cases. The task of extracting graphic material greatly complicates the process, since the recognition should not work on graphic material. You also need to minimize operations to improve the performance of the final software product.
2. The purpose and objectives of the study
The purpose of the study is to analyze the existing methods of text recognition and the selection of graphic material on the original image, as well as creating your own software product based on them.
The following are the main research objectives.
- Consider pre-processing filters for the original image.
- Learn the methods of segmentation of text and graphic material.
- Generate a neural network model for recognition.
- Build the results into an output formatted file and make a check.
3. Review of research and development
The research topic is extremely popular both in the international and national communities. Consider the most promising of them.
3.1 Overview of international sources
In Thomas Kollar, Jonathan Schmid «Optical Character Segmentation and Recognition from a Rochester Flag» [2] , the problem of text recognition on the color flag of Rochester was studied. The authors also proposed a number of solutions to eliminate inaccuracies. Work was carried out on image analysis, highlighting distortions and eliminating them.
In the book Shunji Mori, Hirobumi Nishida, Hiromitsu Yamada «Optical Character Recognition» [3], the first comprehensive review of the preprocessing, feature extraction and systematic comparison was conducted. The book includes many original research materials and examples, which makes it an indispensable guide to text recognition.
The article Ravina Mithe, Supriya Indalkar, Nilam Divekar «Optical Character Recognition» [4] shows the device of the industrial text recognition library "Tesseract". This material clearly articulates the algorithm of text recognition by this library, including a description of the neural network. The described system is designed to recognize scanned documents and is somewhat outdated.
In Simon Haykin's book «Нейронные сети. Полный курс» [5] covers the main paradigms of artificial neural networks. The presented material contains a rigorous mathematical substantiation of all neural network paradigms, is illustrated with examples, a description of computer experiments, contains many practical problems, as well as an extensive bibliography. The book also analyzes the role of neural networks in solving image recognition, control and signal processing tasks. The structure of the book is very convenient for developing courses of training in neural networks and intelligent computing.
3.2 Review of national sources
The article by K.N. Kasian, V.V. Bratchikov, V.V. Shkarupilo «Разработка модифицированного метода распознавания текста на стандартизированном изображении» [6] was carried out analysis and comparison of template methods based on neural network. This work allows you to visually see ways to improve the quality of recognition in certain conditions.
An article by Anna Balakhontseva, Alexander Godob, Nguyen Thien’s «Система распознавания символов на изображениях со сложным фоном» [7] proposed an efficient segmentation algorithm that uses the shortest path method pixel brightness to calculate cuts between characters. Character recognition is based on a curvature scale space algorithm.
In Yevgeny Borisov’s work «Сегментация изображения текста» [8], the classic principle of source text segmentation into lines, words and letters that can be recognized by a neural network is considered.
3.3 Local Source Overview
DonNTU has repeatedly raised the topic of text recognition in the course of analyzing and solving various tasks.
The article Sokolova N., Ruchkina K. «Обзор существующих методов оффлайн распознавания последовательностей рукописных символов» [9] highlights the main task of offline handwriting recognition. The types of offline recognition are considered. The existing methods and algorithms are described, compared, the advantages and disadvantages are highlighted. Later, in the abstract «Исследование и разработка метода распознавания рукописных цифр» [10], an algorithm on the specified topic was developed and tested in practice.
In the article Sosenkova A., Sekirina A. «Определение номерных знаков транспорта с помощью методов обработки изображений» [11] addresses the need for developing a system for license plate recognition. The analysis of image processing, normalization and segmentation methods was performed. Character recognition methods for identifying license plates are defined. In the abstract «Определение номерных знаков транспорта с помощью методов обработки изображений» [12], further work was carried out to study and develop our own system on this topic.
In the article Gaydukova N., Savkova E. «Обзор распознавания рукописного текста» [13] reviewed existing text recognition methods. As a result of the analysis, the advantages and disadvantages of the methods were highlighted, and the optimal one was also chosen. Later, in the abstract «Распознавание рукописного текста» [14], the author described his own system on this topic.
The article Lichkanenko I., Pchelkina V. «Методы обработки изображений и распознавания образов для задачи обнаружения номерных знаков транспортных средств» [15] addressed the problems arising in the process of recognition of vehicle license plates. Identified image processing and recognition methods for identifying license plates. In the abstract «Исследование методов и поиск эффективного алгоритма для задачи распознавания номерных знаков транспортных средств» [16], further work was carried out on this topic.
In the abstract Lashchenko K. «Разработка программного обеспечения для распознавания печатного текста дореволюционной русской орфографии» [17] analyzed the problem and described the system to solve it. An efficient segmentation method is provided for further recognition.
4. Recognition of text and selection of graphic material
Recognizing typed text is quite a challenge. It is easy for a person to do this, but the car needs a lot of preparatory action. And only after them recognition occurs.
Three recognition methods are listed below.
- Comparison with the template.
- Recognizing by criteria.
- Recognition using self-learning algorithms.
The last method involves the use of neural networks in one form or another. He is the highest quality among all known methods, but the most resource-intensive.
For the most effective text recognition, you must perform pre-processing and post-processing steps. The operation of the printed text recognition software can be divided into several stages.
Input data are photos of the source text. To improve the recognition accuracy, it is necessary to pre-process the image. Next, the processed image is fed to the segmentation module, where letters and graphic elements are highlighted. These letters are classified using a neural network, and then comes the search and comparison of the final words with a dictionary. As a result, the recognized text and found images are entered into the final formatted document.
4.1 Pre-processing the original image
At the preprocessing stage, it is necessary to improve the image by applying various filters.
Typically, text uses one color. Apply the classic black and white filter to prepare the original image for recognition.
A median filter is used to remove noise. Sample values inside the filter window are sorted in ascending (descending) order; and the value in the middle of the ordered list is sent to the output of the filter. In the case of an even number of samples in the window, the output value of the filter is equal to the average value of two samples in the middle of the ordered list. The window moves along the filtered signal and the calculations are repeated.
To select the text itself, we bring the image to a binary (monochrome) form. The transition boundary in the filter is defined as the average brightness value of the original image. Such a transition will significantly speed up the work of further algorithms.
After these transformations, the text is clearly visible on the image. The resulting file can already be segmented into blocks.
4.2 Highlighting text and graphics
At this stage, you must select the graphic images on the canvas, as well as blocks with text. To do this, we use a “blurring” filter on a monochrome image, which for each bright point paints the neighboring pixels. The power threshold is determined based on the resolution of the source file. Thus, letters and words crawl over each other, turning into a single object and form blocks in which there is either a graphic image or text.
We define the boundaries of the blocks in the image for further work. We use the classic "magic wand" algorithm. At the beginning, a shaded pixel is randomly selected on a monochrome smeared image. Then, in the vicinity of the selected point, all pixels with the same color will be painted until there are no filled points at the original object. Find the shaded extreme points on the x-axis and ordinates of the object in question in the block. These will be the borders on the original image.
By the painted matrix of the “magic wand” we copy the object for recognition from the source monochrome file, and also save the original coordinates in memory. This way we will find all the recognition blocks and they will not intersect.
For found blocks, you need to determine the type (image or text). This is done by the user through the program interface. If, in the process of further segmentation of the text, words and lines are not found in the block being processed, then this block automatically changes its type to an image.
For further recognition, you must select lines, words and symbols in each text block.
The search for rows in the processed block is based on a comparison of the average brightness value in horizontal pixel lines. Accordingly, the line of text will be located where its brightness will be noticeably higher than zero.
The word search is similar to the string search. We use the low power blur filter in order to fuse the letters into a single object, but leave the space between words. After that, we search for the boundaries of words based on an estimate of the average brightness value of vertical pixel lines. Accordingly, the word will be located where its brightness will be noticeably higher than zero.
Searching for characters in a word is different from searching for strings and words, since letters can sometimes float on each other. To search for characters in a word, you must first create a table of local brightness minima. Then you need to remove the false delimiters. To do this, we delete the column indices of pixels, the average brightness of which is in the vicinity of the right and left above the boundary value determined experimentally for each language and font. To increase accuracy, you can do the previous operation separately for the top of the letter, middle and bottom. This is especially true for letters such as "U", "H", "M", etc.
The result of the segmentation operation is a symbol attached to the corresponding objects of words, lines and blocks, ready to be recognized by the neural network.
Figure 1 shows the algorithm for preprocessing and segmentation.

Figure 1 – Algorithm of preprocessing and segmentation
(animation: 9 frames, 1 second interval between frames, 48 kilobytes)
4.3 Text recognition
Artificial neural networks are widely used for character recognition. Algorithms that use neural networks for character recognition are often constructed as follows. The character image (raster) arriving at recognition is reduced to a certain standard size. As a rule, a 16x16 pixel raster is used. The brightness values in the nodes of the normalized raster are used as input parameters of the neural network. The number of output parameters of the neural network equals the number of recognizable characters. The recognition result is a symbol that corresponds to the largest of the values of the output vector of the neural network. Improving the reliability of such algorithms is usually associated either with the search for more informative input features or with the increasing complexity of the neural network structure [18].
Figure 2 shows a diagram of a neural network.
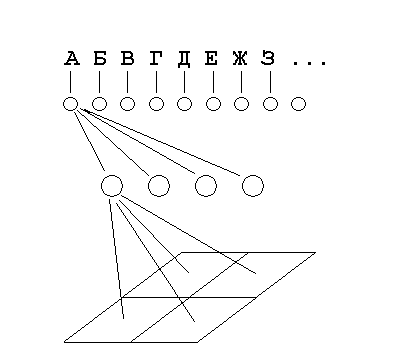
Figure 2 – Neural network diagram
A two-layer neural network was chosen to implement recognition. The first layer is compared by the brightness value of the original symbol. On the second layer there is a comparison by contours.
During the recognition process, the program will be able to learn when the user edits errors.
4.4 Summary Output
The results of the text recognition complex with the selection of graphic material will be displayed and stored as formatted text. They are supposed to be placed into frames according to the coordinates of the source blocks. The text will be framed to suit the appropriate font size. Graphic materials will be transferred from the source image to the corresponding coordinates.
To increase the accuracy of text recognition, the user can use the function of comparing words with an extensive dictionary in automatic or manual mode.
Conclusions
As a result, the task was considered text recognition and selection of graphic material. The focus is on the segmentation of symbols and graphic material. The main algorithm of the developed program is considered, taking into account the peculiarities of the source data. The analysis of various scientific papers on this subject.
List of sources
- Шумский А.А. Программное средство распознавания печатного текста / А.А.Шумский, Е.В.Бычкова // ИУСМКМ – Донецк : Сборник материалов VIII Международной научно-технической конференции в рамках III Международного Научного форума ДНР, 2017. – С. 402.
- Thomas K. Optical Character Segmentation and Recognition from a Rochester Flag / K.Thomas, S.Jonathan [Electronic resource]. - Access mode: https://www.cs.rochester.edu/~brown/242/assts/termprojs/vision.pdf
- Shunji M. Optical Character Recognition / N. Nedjah, L.M. Mourelle // Wiley. – New Jersey, 1999. – p. 560.
- Ravina M. Optical Character Recognition / M.Ravina, I.Supriya, D.Nilam [Electronic resource]. - Access mode: https://pdfs.semanticscholar.org/6a4b/4f04d...
- Саймон Х. Нейронные сети: полный курс / Х.Саймон // Вильямс. - Москва, 2006. - с. 1104.
- Касьян К.Н. Разработка модифицированного метода распознавания текста на стандартизированном изображении / К.Н.Касьян, В.В.Братчиков, В.В.Шкарупило [Electronic resource]. - Access mode: http://journals.uran.ua/eejet/article/download/43047/41599
- Балахонцева А. Система распознавания символов на изображениях со сложным фоном / А.Балахонцева, А.Годоба, Н.Тьен [Electronic resource]. - Access mode: http://www.graphicon.ru/html/2013/papers/250-253.pdf
- Борисов Е. Сегментация изображения текста / Е.Борисов [Electronic resource]. - Access mode: http://mechanoid.kiev.ua/cv-text-image-segmentator.html
- Соколов Н.Г. Обзор существующих методов оффлайн распознавания последовательностей рукописных символов / Н.Г.Соколов, К.А.Ручкин [Electronic resource]. - Access mode: http://masters.donntu.ru/2017/fknt/sokolov/library/recognition.pdf
- Соколов Н.Г. Исследование и разработка метода распознавания рукописных цифр / Н.Г.Соколов [Electronic resource]. - Access mode: http://masters.donntu.ru/2017/fknt/sokolov/diss/index.htm
- Сосенков А.Ю. Определение номерных знаков транспорта с помощью методов обработки изображений / А.Ю.Сосенков, А.И.Секирин [Electronic resource]. - Access mode: http://masters.donntu.ru/2015/fknt/sosenkov/library/article1.htm
- Сосенков А.Ю. Определение номерных знаков транспорта с помощью методов обработки изображений / А.Ю.Сосенков [Electronic resource]. - Access mode: http://masters.donntu.ru/2015/fknt/sosenkov/diss/index.htm
- Гайдуков Н.П. Обзор методов распознавания рукописного текста / Н.П.Гайдуков, Е.О.Савкова [Electronic resource]. - Access mode: http://masters.donntu.ru/2012/fknt/gaydukov/library/5_gaydukov.pdf
- Гайдуков Н.П. Распознавание рукописного текста / Н.П.Гайдуков [Electronic resource]. - Access mode: http://masters.donntu.ru/2012/fknt/gaydukov/diss/index.htm
- Личканенко И.С. Методы обработки изображений и распознавания образов для задачи обнаружения номерных знаков транспортных средств / И.С.Личканенко, В.Н.Пчелкин [Electronic resource]. - Access mode: http://masters.donntu.ru/2013/fknt/lichkanenko/library/article1.htm
- Личканенко И.С. Исследование методов и поиск эффективного алгоритма для задачи распознавания номерных знаков транспортных средств / И.С.Личканенко [Electronic resource]. - Access mode: http://masters.donntu.ru/2013/fknt/lichkanenko/diss/index.htm
- Лащенко К.С. Разработка программного обеспечения для распознавания печатного текста дореволюционной русской орфографии / К.С.Лащенко [Electronic resource]. - Access mode: http://masters.donntu.ru/2017/fknt/lashchenko/diss/index.htm
- Мисюрёв А.В. Использование искусственных нейронных сетей для распознавания рукопечатных символов / А.В.Мисюрёв [Electronic resource]. - Access mode: http://ocrai.narod.ru/hp.html