
Реферат по теме выпускной работы
Внимание! Данный реферат относится к еще не завершенной работе. Примерная дата завершения: Июнь 2019 г. Обращайтесь к автору после указанной даты для получения окончательного варианта.
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Распознавание текста и выделение графического материала
- 4.1 Предобработка исходного изображения
- 4.2 Выделение текста и графики
- 4.3 Распознавание текста
- 4.4 Обобщение выходных данных
- Выводы
- Список источников
Введение
В век информационных технологий и электронных подписей обычные бумажные документы ничуть не утратили своей силы. Работникам различных сфер деятельности зачастую приходится вручную набирать объемные тексы из-за отсутствия или невозможности достать электронные исходники. Сам текст может обтекать различный графический материал, что усложняет этот процесс. Для его автоматизации существуют системы распознавания печатного текста. Данные системы бывают в виде сервисов и приложений под разные платформы (Windows, Android и другие) [1].
1. Актуальность темы
Сейчас существует множество систем для распознавания текста, однако лишь малая их часть способна выделять графический материал и переносить его в итоговый электронный документ с сохранением его положения.
Для этого существует множество методов сегментации исходного изображения. Каждый эффективен в разных случаях. Задача выделения графического материала сильно усложняет процесс, поскольку распознавание не должно срабатывать на графическом материале. Также требуется минимизировать операции для улучшения быстродействия итогового программного продукта.
2. Цель и задачи исследования
Целью исследования является анализ существующих методов распознания текста и выделение графического материала на исходном изображении, а также создания собственного программного продукта на их основе.
Ниже приведены основные задачи исследования.
- Рассмотреть фильтры предобработки исходного изображения.
- Изучить методы сегментации текста и графического материала.
- Сформировать модель нейронной сети для распознавания.
- Скомпоновать результаты в выходной форматированный файл и сделать проверку.
3. Обзор исследований и разработок
Исследуемая тема крайне популярна как в международных сообществах, так и в национальных. Рассмотрим наиболее перспективные из них.
3.1 Обзор международных источников
В работе Thomas Kollar, Jonathan Schmid «Optical Character Segmentation and Recognition from a Rochester Flag» [2] была изучена проблема распознавания текста на цветном флаге города Рочестер. Также авторы предложили ряд решений для устранения неточностей. Была проведена работа по анализу изображения, выделению искажений и их ликвидации.
В книге Shunji Mori, Hirobumi Nishida, Hiromitsu Yamada «Optical Character Recognition» [3] проведено первое всеобъемлющее рассмотрение этапов предварительной обработки, выделения признаков и их систематического сопоставления. В книгу включено множество оригинальных исследовательских материалов и примеров, что делает ее незаменимым руководством по распознаванию текста.
В статье Ravina Mithe, Supriya Indalkar, Nilam Divekar «Optical Character Recognition» [4] приведено устройство промышленной библиотеки распознавания текста «Tesseract». В данном материале четко сформулирован алгоритм работы распознавания текста данной библиотекой, включая описание нейронной сети. Описанная система предназначена для распознавания отсканированных документов и несколько устарела.
В книге Саймона Хайкина «Нейронные сети. Полный курс» [5] рассматриваются основные парадигмы искусственных нейронных сетей. Представленный материал содержит строгое математическое обоснование всех нейросетевых парадигм, иллюстрируется примерами, описанием компьютерных экспериментов, содержит множество практических задач, а также обширную библиографию. В книге также анализируется роль нейронных сетей при решении задач распознавания образов, управления и обработки сигналов. Структура книги очень удобна для разработки курсов обучения нейронным сетям и интеллектуальным вычислениям.
3.2 Обзор национальных источников
В статье К.Н.Касьян, В.В.Братчиков, В.В.Шкарупило «Разработка модифицированного метода распознавания текста на стандартизированном изображении» [6] был проведен анализ и сравнение шаблонных методов на основе нейронной сети. Данная работа позволяет наглядно увидеть способы по улучшению качества распознавания в определенных условиях.
В статье Анны Балахонцевой, Александра Годоба, Нгуена Тьена «Система распознавания символов на изображениях со сложным фоном» [7] предложен эффективный алгоритм сегментации, который использует метод кратчайшего пути по яркости пикселей для расчета разрезов между символами. Распознавание символов основывается на алгоритме масштабного пространства кривизны.
В работе Евгения Борисова «Сегментация изображения текста» [8] рассмотрен классический принцип сегментации исходного текста на строки, слова и буквы, пригодные для распознавания нейронной сетью.
3.3 Обзор локальных источников
В ДонНТУ не раз поднималась тема распознавания текста в ходе выполнения анализа и решения различных задач.
В статье Соколова Н.Г., Ручкина К.А. «Обзор существующих методов оффлайн распознавания последовательностей рукописных символов» [9] выделена основная задача оффлайн-распознавания рукописных символов. Рассмотрены виды оффлайн-распознавания. Описаны существующие методы и алгоритмы, выполнено их сравнение, выделены достоинства и недостатки. В дальнейшев в реферате «Исследование и разработка метода распознавания рукописных цифр» [10] был разработан и проверен на практике алгоритм по указанной теме.
В статье Сосенкова А.Ю., Секирина А.И. «Определение номерных знаков транспорта с помощью методов обработки изображений» [11] рассмотрена потребность в разработке системы для распознавания номерных знаков. Выполнен анализ методов обработки изображений, нормализации и сегментации. Определены методы распознавания символов для определения номерных знаков. В реферате «Определение номерных знаков транспорта с помощью методов обработки изображений» [12] была проведена дальнейшая работа по изучению и разработке собственной системы по указанной теме.
В статье Гайдукова Н.П., Савковой Е.О. «Обзор распознавания рукописного текста» [13] рассмотрены существующие методы распознавания текстов. В результате анализа, были выделены преимущества и недостатки методов, а также был выбран оптимальный. В дальнейшев в реферате «Распознавание рукописного текста» [14] автор описал собственную систему по указанной теме.
В статье Личканенко И.С., Пчелкина В.Н. «Методы обработки изображений и распознавания образов для задачи обнаружения номерных знаков транспортных средств» [15] рассмотрены задачи, возникающие в процессе распознавания номерных знаков транспортных средств. Определены методы обработки изображений и распознавания для выявления номерных знаков. В реферате «Исследование методов и поиск эффективного алгоритма для задачи распознавания номерных знаков транспортных средств» [16] была проведена дальнейшая работа по указанной теме.
В реферате Лащенко К.С. «Разработка программного обеспечения для распознавания печатного текста дореволюционной русской орфографии» [17] проведен анализ проблемы описана система для ее решения. Приведен эффективный метод сегментации для дальнейшего распознавания.
4. Распознавание текста и выделение графического материала
Распознавание печатного текста является довольно сложной задачей. Человеку это дается просто, но машине требуется много подготовительных действий. И только после них происходит распознавание.
Ниже приведены три метода распознавания.
- Сравнение с шаблоном.
- Распознавание по критериям.
- Распознавание при помощи самообучающихся алгоритмов.
Последний из методов подразумевает использование нейронных сетей в том или ином виде. Именно он является наиболее качественным среди всех известных методов, однако наиболее ресурсоемким.
Для максимально эффективного распознавания текста необходимо выполнить действия по предобработке и постобработке. Работу программного средства распознавания печатного текста можно поделить на несколько этапов, которые изображены на рисунке 1.
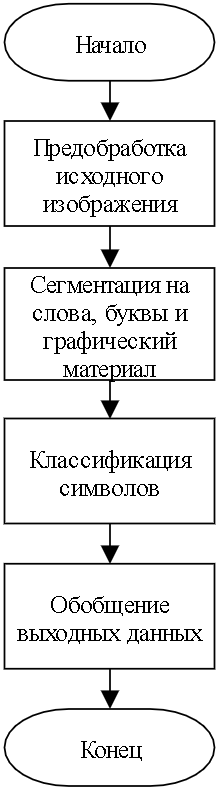
Рисунок 1 – Обобщенные этапы работы программы
Входными данными являются фотографии исходного текста. Для повышения точности распознавания необходимо провести предобработку изображения. Далее обработанное изображение поступает на модуль сегментации, где выделяются буквы и графические элементы. Данные буквы классифицируются с помощью нейронной сети, а затем идет поиск и сравнение итоговых слов со словарем. В результате в итоговый документ с форматированием вносится распознанный текст и найденные изображения.
4.1 Предобработка исходного изображения
На этапе предобработки необходимо улучшить изображение, применив различные фильтры.
Обычно текст использует один цвет. Применим классический черно-белый фильтр чтобы подготовить исходное изображение к распознаванию.
Для удаления шумов используется медианный фильтр. Значения отсчётов внутри окна фильтра сортируются в порядке возрастания (убывания); и значение, находящееся в середине упорядоченного списка, поступает на выход фильтра. В случае чётного числа отсчётов в окне выходное значение фильтра равно среднему значению двух отсчётов в середине упорядоченного списка. Окно перемещается вдоль фильтруемого сигнала и вычисления повторяются.
Для выделения самого текста приведем изображение к бинарному (монохромному) виду. Границу перехода в фильтре определим как среднее значение яркости исходного изображения. Такой переход позволит значительно ускорить работу дальнейших алгоритмов.
После данных преобразований на изображении четко виден текст. Получившийся файл уже можно сегментировать на блоки.
4.2 Выделение текста и графики
На данном этапе необходимо выделить графические изображения на холсте, а также блоки с текстом. Для этого используем на монохромном изображении фильтр «размазывания», который для каждой яркой точки закрашивает соседние пиксели. Порог мощности определяется исходя из разрешения исходного файла. Таким образом буквы и слова наползают друг на друга, превращаясь в единый объект и сформируют блоки, в которых находится или графическое изображение, или текст.
Определим границы блоков на изображении для дальнейшей работы. Воспользуемся классическим алгоритмом «волшебной палочки». В начале случайным образом выбирается закрашенный пиксель на монохромном размазанном изображении. Затем в окрестностях выбранной точки закрашиваются все пиксели с таким же цветом пока не останется закрашенных точек у исходного объекта. Найдем закрашенные крайние точки на оси абсцисс и ординат рассматриваемого объекта в блоке. Это и будут границы на исходном изображении.
По закрашенной матрице «магической палочки» скопируем объект для распознавания из исходного монохромного файла, а также сохраним в памяти исходные координаты. Таким образом мы найдем все блоки для распознавания, и они не будут пересекаться.
Для найденных блоков необходимо определить тип (изображение или текст). Это делает пользователь через интерфейс программы. Если в процессе дальнейшей сегментации текста не будут найдены слова и строки в обрабатываемом блоке, то тогда этот блок автоматически меняет свой тип на изображение.
Для дальнейшего распознавания необходимо выделить в каждом текстовом блоке строки, слова и символы.
Поиск строк в обработанном блоке происходит на основе сравнения среднего значения яркости в горизонтальных пиксельных линиях. Соответственно строка текста будет находится там, где ее яркость будет заметно выше нуля.
Поиск слов похож на поиск строк. Воспользуемся фильтром размытия небольшой мощности с целью сплавить буквы в единый объект, но оставить интервал между словами. После этого проведем поиск границ слов на основе оценки среднего значения яркости вертикальных пиксельных линий. Соответственно слово будет находится там, где ее яркость будет заметно выше нуля.
Поиск символов в слове отличается от поиска строк и слов, поскольку буквы иногда могут наплывать друг на друга. Для поиска символов в слове необходимо сначала составить таблицу локальных минимумов яркости. Затем нужно удалить ложные разделители. Для этого удаляем индексы столбцов пикселей, средняя яркость которых в окрестностях справа и слева выше граничного значения, определенного экспериментально для каждого языка и шрифта. Для увеличения точности можно проделать предыдущую операцию отдельно для верха буквы, середины и низа. Это особенно актуально для таких букв, как «Ц», «Н», «П» и т.д.
Результатом операции сегментирования является символ, привязанный к соответствующим объектам слов, строк и блоков, готовый к распознаванию нейронной сетью.
На рисунке 2 продемонстрирован алгоритм работы предобработки и сегментации.

Рисунок 2 – Алгоритм работы предобработки и сегментации
(анимация: 9 кадров, 1сек интервал между кадрами, 48 килобайт)
4.3 Распознавание текста
Искусственные нейронные сети достаточно широко используются при распознавании символов. Алгоритмы, использующие нейронные сети для распознавания символов, часто строятся следующим образом. Поступающее на распознавание изображение символа (растр) приводится к некоторому стандартному размеру. Как правило, используется растр размером 16х16 пикселов. Значения яркости в узлах нормализованного растра используются в качестве входных параметров нейронной сети. Число выходных параметров нейронной сети равняется числу распознаваемых символов. Результатом распознавания является символ, которому соответствует наибольшее из значений выходного вектора нейронной сети. Повышение надежности таких алгоритмов связано, как правило, либо с поиском более информативных входных признаков, либо с усложнением структуры нейронной сети [18].
На рисунке 3 изображена схема нейронной сети.
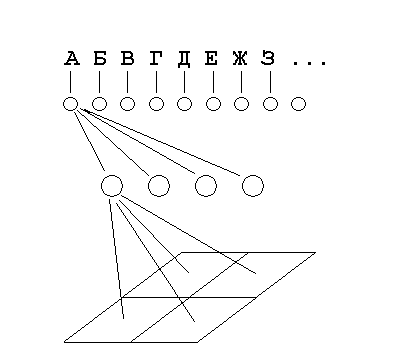
Рисунок 3 – Схема нейронной сети
Для реализации распознавания была выбрана двухслойная нейронная сеть. На первом слое происходит сравнение по значению яркости исходного символа. На втором слое происходит сравнение по контурам.
В процессе распознавания программа сможет обучатся когда пользователь будет редактировать ошибки.
4.4 Обобщение выходных данных
Результаты работы комплекса распознавания текста с выделением графического материала будут выводится и сохранятся в виде форматированного текста. Предполагается их размещение в рамки по координатам исходных блоков. Текст будет вписан в рамку с учетом подходящего размера шрифта. Графические материалы будут перенесены с исходного изображения по соответствующим координатам.
Для увеличения точности распознавания текста пользователь может использовать функцию сравнения слов с обширным словарем в автоматическом или ручном режиме.
Выводы
В результате работы была рассмотрена задача распознавания текста и выделения графического материала. Основное внимание уделено сегментации символов и графического материала. Рассмотрен основной алгоритм работы разрабатываемой программы с учетом особенностей исходных данных. Проведен анализ различных научных работ по данной тематике.
Список источников
- Шумский А.А. Программное средство распознавания печатного текста / А.А.Шумский, Е.В.Бычкова // ИУСМКМ – Донецк : Сборник материалов VIII Международной научно-технической конференции в рамках III Международного Научного форума ДНР, 2017. – С. 402.
- Thomas K. Optical Character Segmentation and Recognition from a Rochester Flag / K.Thomas, S.Jonathan [Электронный ресурс]. – Режим доступа: https://www.cs.rochester.edu/~brown/242/assts/termprojs/vision.pdf
- Shunji M. Optical Character Recognition / N. Nedjah, L.M. Mourelle // Wiley. – New Jersey, 1999. – p. 560.
- Ravina M. Optical Character Recognition / M.Ravina, I.Supriya, D.Nilam [Электронный ресурс]. – Режим доступа: https://pdfs.semanticscholar.org/6a4b/4f04d...
- Саймон Х. Нейронные сети: полный курс / Х.Саймон // Вильямс. - Москва, 2006. - с. 1104.
- Касьян К.Н. Разработка модифицированного метода распознавания текста на стандартизированном изображении / К.Н.Касьян, В.В.Братчиков, В.В.Шкарупило [Электронный ресурс]. – Режим доступа: http://journals.uran.ua/eejet/article/download/43047/41599
- Балахонцева А. Система распознавания символов на изображениях со сложным фоном / А.Балахонцева, А.Годоба, Н.Тьен [Электронный ресурс]. – Режим доступа: http://www.graphicon.ru/html/2013/papers/250-253.pdf
- Борисов Е. Сегментация изображения текста / Е.Борисов [Электронный ресурс]. – Режим доступа: http://mechanoid.kiev.ua/cv-text-image-segmentator.html
- Соколов Н.Г. Обзор существующих методов оффлайн распознавания последовательностей рукописных символов / Н.Г.Соколов, К.А.Ручкин [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2017/fknt/sokolov/library/recognition.pdf
- Соколов Н.Г. Исследование и разработка метода распознавания рукописных цифр / Н.Г.Соколов [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2017/fknt/sokolov/diss/index.htm
- Сосенков А.Ю. Определение номерных знаков транспорта с помощью методов обработки изображений / А.Ю.Сосенков, А.И.Секирин [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2015/fknt/sosenkov/library/article1.htm
- Сосенков А.Ю. Определение номерных знаков транспорта с помощью методов обработки изображений / А.Ю.Сосенков [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2015/fknt/sosenkov/diss/index.htm
- Гайдуков Н.П. Обзор методов распознавания рукописного текста / Н.П.Гайдуков, Е.О.Савкова [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2012/fknt/gaydukov/library/5_gaydukov.pdf
- Гайдуков Н.П. Распознавание рукописного текста / Н.П.Гайдуков [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2012/fknt/gaydukov/diss/index.htm
- Личканенко И.С. Методы обработки изображений и распознавания образов для задачи обнаружения номерных знаков транспортных средств / И.С.Личканенко, В.Н.Пчелкин [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2013/fknt/lichkanenko/library/article1.htm
- Личканенко И.С. Исследование методов и поиск эффективного алгоритма для задачи распознавания номерных знаков транспортных средств / И.С.Личканенко [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2013/fknt/lichkanenko/diss/index.htm
- Лащенко К.С. Разработка программного обеспечения для распознавания печатного текста дореволюционной русской орфографии / К.С.Лащенко [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2017/fknt/lashchenko/diss/index.htm
- Мисюрёв А.В. Использование искусственных нейронных сетей для распознавания рукопечатных символов / А.В.Мисюрёв [Электронный ресурс]. – Режим доступа: http://ocrai.narod.ru/hp.html