
Реферат за темою випускної роботи
Увага! Даний реферат відноситься до ще не завершеної роботи. Орієнтовна дата завершення: Черв 2019 р Звертайтеся до автора після зазначеної дати для отримання остаточного варіанту.
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і завдання дослідження
- 3. Огляд досліджень і розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Розпізнавання тексту і виділення графічного матеріалу
- 4.1 Передобробка вихідного зображення
- 4.2 Виділення тексту та графіки
- 4.3 Розпізнавання тексту
- 4.4 Узагальнення вихідних даних
- Висновки
- Список джерел
Вступ
В епоху інформаційних технологій та електронних підписів звичайні паперові документи нітрохи не втратили своєї сили. Працівникам різних сфер діяльності часто доводиться вручну набирати об'ємні текс через відсутність або неможливості дістати електронні вихідні. Сам текст може обтікати різний графічний матеріал, що ускладнює цей процес. Для його автоматизації існують системи розпізнавання друкованого тексту. Дані системи бувають у вигляді сервісів і додатків під різні платформи (Windows, Android та інші) [1].
1. Актуальність теми
Зараз існує безліч систем для розпізнавання тексту, однак лише мала їх частина здатна виділяти графічний матеріал і переносити його в підсумковий електронний документ зі збереженням його положення.
Для цього існує безліч методів сегментації вихідного зображення. Кожен ефективний в різних випадках. Завдання виділення графічного матеріалу сильно ускладнює процес, оскільки розпізнавання не має спрацьовувати на графічному матеріалі. Також потрібно мінімізувати операції для поліпшення швидкодії підсумкового програмного продукту.
2. Мета і завдання дослідження
Метою дослідження є аналіз існуючих методів розпізнавання тексту і виділення графічного матеріалу на оригінальному документі, а також створення власного програмного продукту на їх основі.
Нижче наведені основні завдання дослідження.
- Розглянути фільтри предобработки вихідного зображення.
- Вивчити методи сегментації тексту і графічного матеріалу.
- Сформувати модель нейронної мережі для розпізнавання.
- Скомпонувати результати у вихідний форматований файл і зробити перевірку.
3. Огляд досліджень і розробок
Досліджувана тема вкрай популярна як в міжнародних співтовариствах, так і в національних. Розглянемо найбільш перспективні з них.
3.1 Огляд міжнародних джерел
В роботі Thomas Kollar, Jonathan Schmid «Optical Character Segmentation and Recognition from a Rochester Flag» [2] була вивчена проблема розпізнавання тексту на кольоровому прапорі міста Рочестер. Також автори запропонували ряд рішень для усунення неточностей. Була проведена робота з аналізу зображення, виділенню спотворень і їх ліквідації.
В книзі Shunji Mori, Hirobumi Nishida, Hiromitsu Yamada «Optical Character Recognition» [3] проведено перше всеосяжне розгляд етапів попередньої обробки, виділення ознак і їх систематичного зіставлення. До книги включено безліч оригінальних дослідних матеріалів і прикладів, що робить її незамінним посібником з розпізнаванню тексту.
У статті Ravina Mithe, Supriya Indalkar, Nilam Divekar «Optical Character Recognition» [4] наведено пристрій промислової бібліотеки розпізнавання тексту «Tesseract». В даному матеріалі чітко сформульований алгоритм роботи розпізнавання тексту даної бібліотекою, включаючи опис нейронної мережі. Описана система призначена для розпізнавання відсканованих документів і дещо застаріла.
В книзі Саймона Хайкіна «Нейронные сети. Полный курс» [5] розглядаються основні парадигми штучних нейронних мереж. Представлений матеріал містить суворе математичне обґрунтування всіх нейромережевих парадигм, ілюструється прикладами, описом комп'ютерних експериментів, містить безліч практичних завдань, а також велику бібліографію. У книзі також аналізується роль нейронних мереж при вирішенні задач розпізнавання образів, управління і обробки сигналів. Структура книги дуже зручна для розробки курсів навчання нейронних мереж і інтелектуальним обчислень.
3.2 Огляд національних джерел
У статті К.Н.Касьян, В.В.Братчіков, В.В.Шкарупіло «Разработка модифицированного метода распознавания текста на стандартизированном изображении» [6] був проведений аналіз і порівняння шаблонних методів на основі нейронної мережі. Дана робота дозволяє наочно побачити способи щодо поліпшення якості розпізнавання в певних умовах.
У статті Анни Балахонцевой, Олександра Годоба, Нгуєна Тьена «Система распознавания символов на изображениях со сложным фоном» [7] запропонований ефективний алгоритм сегментації, який використовує метод найкоротшого шляху по яскравості пікселів для розрахунку розрізів між символами. Розпізнавання символів грунтується на алгоритмі масштабного простору кривизни.
В роботі Євгенія Борисова «Сегментация изображения текста» [8] розглянуто класичний принцип сегментації початкового тексту на рядки, слова і букви, придатні для розпізнавання нейронною мережею.
3.3 Огляд локальних джерел
В ДонНТУ не раз піднімалася тема розпізнавання тексту в ході виконання аналізу і вирішення різних завдань.
У статті Соколова Н.Г., Ручкина К.А. «Обзор существующих методов оффлайн распознавания последовательностей рукописных символов» [9] виділена основна задача оффлайн-розпізнавання рукописних символів. Розглянуто види оффлайн-розпізнавання. Описано існуючі методи і алгоритми, виконано їх порівняння, виділені переваги і недоліки. Надалі в рефераті «Исследование и разработка метода распознавания рукописных цифр» [10] був розроблений і перевірений на практиці алгоритм із зазначеної теми.
У статті Сосенкова А.Ю., Секіріна А.І. «Определение номерных знаков транспорта с помощью методов обработки изображений» [11] розглянута потреба в розробці системи для розпізнавання номерних знаків. Виконано аналіз методів обробки зображень, нормалізації і сегментації. Визначено методи розпізнавання символів для визначення номерних знаків. У рефераті «Определение номерных знаков транспорта с помощью методов обработки изображений» [12] була проведена подальша робота по вивченню і розробці власної системи із зазначеної теми.
У статті Гайдукова Н.П., Савкова Е.О. «Обзор распознавания рукописного текста» [13] розглянуті існуючі методи розпізнавання текстів. В результаті аналізу, були виділені переваги та недоліки методів, а також був вибраний оптимальний. Надалі в рефераті «Распознавание рукописного текста» [14] автор описав власну систему із зазначеної теми.
У статті Лічканенко І.С., Пчелкина В.Н. «Методы обработки изображений и распознавания образов для задачи обнаружения номерных знаков транспортных средств» [15] розглянуті завдання, що виникають в процесі розпізнавання номерних знаків транспортних засобів. Визначено методи обробки зображень і розпізнавання для виявлення номерних знаків. У рефераті «Исследование методов и поиск эффективного алгоритма для задачи распознавания номерных знаков транспортных средств» [16] була проведена подальша робота із зазначеної теми.
В рефераті Лащенко К.С. «Разработка программного обеспечения для распознавания печатного текста дореволюционной русской орфографии» [17] проведено аналіз проблеми описана система для її вирішення. Наведено ефективний метод сегментації для подальшого розпізнавання.
4. Розпізнавання тексту і виділення графічного матеріалу
Розпізнавання друкованого тексту є досить складним завданням. Людині це дається просто, але машині потрібно багато підготовчих дій. І тільки після них відбувається розпізнавання.
Нижче наведені три методу розпізнавання.
- Порівняння з шаблоном.
- Розпізнавання за критеріями.
- Розпізнавання за допомогою самообучающихся алгоритмів.
Останній з методів має на увазі використання нейронних мереж в тому чи іншому вигляді. Саме він є найбільш якісним серед всіх відомих методів, однак найбільш ресурсномістких.
Для максимально ефективного розпізнавання тексту необхідно виконати дії по передобробці і постобробці. Роботу програмного засобу розпізнавання друкованого тексту можна поділити на кілька етапів.
Вхідними даними є фотографії вихідного тексту. Для підвищення точності розпізнавання необхідно провести предобработку зображення. Далі оброблене зображення надходить на модуль сегментації, де виділяються букви і графічні елементи. Дані букви класифікуються за допомогою нейронної мережі, а потім йде пошук і порівняння підсумкових слів зі словником. В результаті в підсумковий документ з форматуванням вноситься розпізнаний текст і зображення, які знайдете.
4.1 Передобробка вихідного зображення
На етапі попередньої обробки необхідно поліпшити зображення, застосувавши різні фільтри.
Зазвичай текст використовує один колір. Застосуємо класичний чорно-білий фільтр щоб підготувати вихідне зображення до розпізнавання.
Для видалення шумів використовується медіанний фільтр. Значення відліків усередині вікна фільтра сортуються в порядку зростання (спадання); і значення, що знаходиться в середині упорядкованого списку, надходить на вихід фільтра. У разі парного числа відліків у вікні вихідне значення фільтра дорівнює середньому значенню двох відліків в середині упорядкованого списку. Вікно переміщається уздовж фильтруемого сигналу і обчислення повторюються.
Для виділення самого тексту наведемо зображення до бінарним (монохромного) виду. Кордон переходу в фільтрі визначимо як середнє значення яскравості вихідного зображення. Такий перехід дозволить значно прискорити роботу подальших алгоритмів.
Після даних перетворень на зображенні чітко видно текст. Одержаний файл вже можна сегментувати на блоки.
4.2 Виділення тексту та графіки
На даному етапі необхідно виділити графічні зображення на полотні, а також блоки з текстом. Для цього використовуємо на монохромному зображенні фільтр «розмазування», який для кожної яскравої точки зафарбовує сусідні пікселі. Поріг потужності визначається виходячи з початкового файлу. Таким чином букви і слова наповзають один на одного, перетворюючись в єдиний об'єкт і сформують блоки, в яких знаходиться або графічне зображення, або текст.
Визначимо кордону блоків на зображенні для подальшої роботи. Скористаємося класичним алгоритмом «чарівної палички». На початку випадковим чином вибирається зафарбований піксель на монохромному розмазати зображенні. Потім в околицях обраної точки зафарбовуються всі пікселі з таким же кольором поки не залишиться зафарбованих точок у вихідного об'єкта. Знайдемо зафарбовані крайні точки на осі абсцис і ординат даного об'єкту в блоці. Це і будуть кордону на оригінальному документі.
За зафарбованою матриці «чарівної палички» скопіюємо об'єкт для розпізнавання з вихідного монохромного файлу, а також збережемо в пам'яті вихідні координати. Таким чином ми знайдемо всі блоки для розпізнавання, і вони не будуть перетинатися.
Для знайдених блоків необхідно визначити тип (зображення або текст). Це робить користувач через інтерфейс програми. Якщо в процесі подальшої сегментації тексту не будуть знайдені слова і рядки в оброблюваному блоці, то тоді цей блок автоматично змінює свій тип на зображення.
Для подальшого розпізнавання необхідно виділити в кожному текстовому блоці рядка, слова і символи.
Пошук рядків в обробленому блоці відбувається на основі порівняння середнього значення яскравості в горизонтальних піксельних лініях. Відповідно рядок тексту буде знаходиться там, де її яскравість буде помітно вище нуля.
Пошук слів схожий на пошук рядків. Скористаємося фільтром розмиття невеликої потужності з метою сплавити букви в єдиний об'єкт, але залишити інтервал між словами. Після цього проведемо пошук кордонів слів на основі оцінки середнього значення яскравості вертикальних піксельних ліній. Відповідно слово буде знаходиться там, де її яскравість буде помітно вище нуля.
Пошук символів в слові відрізняється від пошуку рядків і слів, оскільки літери іноді можуть насуватися один на одного. Для пошуку символів в слові необхідно спочатку скласти таблицю локальних мінімумів яскравості. Потім потрібно видалити помилкові роздільники. Для цього видаляємо індекси стовпців пікселів, середня яскравість яких в околицях справа і зліва вище граничного значення, визначеного експериментально для кожної мови і шрифту. Для збільшення точності можна виконати попередню операцію окремо для верху букви, середини і низу. Це особливо актуально для таких букв, як «Ц», «Н», «П» і т.д.
Результатом операції сегментування є символ, прив'язаний до відповідних об'єктів слів, рядків і блоків, готовий до розпізнавання нейронною мережею.
На рисунку 1 продемонстрований алгоритм роботи предобработки і сегментації.

Рисунок 1 – Алгоритм роботи предобработки і сегментації
(анімація: 9 кадрів, 1 сек інтервал між кадрами, 48 кілобайт)
4.3 Розпізнавання тексту
Штучні нейронні мережі досить широко використовуються при розпізнаванні символів. Алгоритми, що використовують нейронні мережі для розпізнавання символів, часто будуються в такий спосіб. Що поступає на розпізнавання зображення символу (растр) приводиться до деякого стандартного розміру. Як правило, використовується растр розміром 16х16 пікселів. Значення яскравості у вузлах нормалізованого растра використовуються в якості вхідних параметрів нейронної мережі. Число вихідних параметрів нейронної мережі дорівнює числу розпізнаваних символів. Результатом розпізнавання є символ, якому відповідає найбільше зі значень вихідного вектора нейронної мережі. Підвищення надійності таких алгоритмів пов'язано, як правило, або з пошуком більш інформативних вхідних ознак, або з ускладненням структури нейронної мережі [18].
На рисунку 2 зображена схема нейронної мережі.
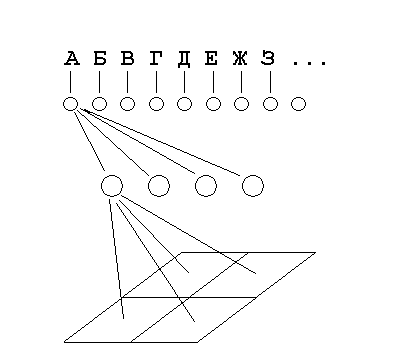
Рисунок 2 – Схема нейронної мережі
Для реалізації розпізнавання була обрана двошаровий нейронна мережа. На першому шарі відбувається порівняння за значенням яскравості вихідного символу. На другому шарі відбувається порівняння по контурах.
В процесі розпізнавання програма зможе навчатися коли користувач буде редагувати помилки.
4.4 Узагальнення вихідних даних
Результати роботи комплексу розпізнавання тексту з виділенням графічного матеріалу будуть виводиться і збережуться у вигляді тексту фіксованої. Передбачається їх розміщення в рамки за координатами вихідних блоків. Текст буде вписаний в рамку з урахуванням відповідного розміру шрифту. Графічні матеріали будуть перенесені з вихідного зображення по відповідним координатам.
Для збільшення точності розпізнавання тексту користувач може використовувати функцію порівняння слів з великим словником в автоматичному або ручному режимі.
Висновки
В результаті роботи була розглянута задача розпізнавання тексту і виділення графічного матеріалу. Основну увагу приділено сегментації символів і графічного матеріалу. Розглянуто основний алгоритм роботи програми, що розробляється з урахуванням особливостей вихідних даних. Проведено аналіз різних наукових робіт з даної тематики.
Список джерел
- Шумский А.А. Программное средство распознавания печатного текста / А.А.Шумский, Е.В.Бычкова // ИУСМКМ – Донецк : Сборник материалов VIII Международной научно-технической конференции в рамках III Международного Научного форума ДНР, 2017. – С. 402.
- Thomas K. Optical Character Segmentation and Recognition from a Rochester Flag / K.Thomas, S.Jonathan [Електронний ресурс]. - Режим доступу: https://www.cs.rochester.edu/~brown/242/assts/termprojs/vision.pdf
- Shunji M. Optical Character Recognition / N. Nedjah, L.M. Mourelle // Wiley. – New Jersey, 1999. – p. 560.
- Ravina M. Optical Character Recognition / M.Ravina, I.Supriya, D.Nilam [Електронний ресурс]. - Режим доступу: https://pdfs.semanticscholar.org/6a4b/4f04d...
- Саймон Х. Нейронные сети: полный курс / Х.Саймон // Вильямс. - Москва, 2006. - с. 1104.
- Касьян К.Н. Разработка модифицированного метода распознавания текста на стандартизированном изображении / К.Н.Касьян, В.В.Братчиков, В.В.Шкарупило [Електронний ресурс]. - Режим доступу: http://journals.uran.ua/eejet/article/download/43047/41599
- Балахонцева А. Система распознавания символов на изображениях со сложным фоном / А.Балахонцева, А.Годоба, Н.Тьен [Електронний ресурс]. - Режим доступу: http://www.graphicon.ru/html/2013/papers/250-253.pdf
- Борисов Е. Сегментация изображения текста / Е.Борисов [Електронний ресурс]. - Режим доступу: http://mechanoid.kiev.ua/cv-text-image-segmentator.html
- Соколов Н.Г. Обзор существующих методов оффлайн распознавания последовательностей рукописных символов / Н.Г.Соколов, К.А.Ручкин [Електронний ресурс]. - Режим доступу: http://masters.donntu.ru/2017/fknt/sokolov/library/recognition.pdf
- Соколов Н.Г. Исследование и разработка метода распознавания рукописных цифр / Н.Г.Соколов [Електронний ресурс]. - Режим доступу: http://masters.donntu.ru/2017/fknt/sokolov/diss/index.htm
- Сосенков А.Ю. Определение номерных знаков транспорта с помощью методов обработки изображений / А.Ю.Сосенков, А.И.Секирин [Електронний ресурс]. - Режим доступу: http://masters.donntu.ru/2015/fknt/sosenkov/library/article1.htm
- Сосенков А.Ю. Определение номерных знаков транспорта с помощью методов обработки изображений / А.Ю.Сосенков [Електронний ресурс]. - Режим доступу: http://masters.donntu.ru/2015/fknt/sosenkov/diss/index.htm
- Гайдуков Н.П. Обзор методов распознавания рукописного текста / Н.П.Гайдуков, Е.О.Савкова [Електронний ресурс]. - Режим доступу: http://masters.donntu.ru/2012/fknt/gaydukov/library/5_gaydukov.pdf
- Гайдуков Н.П. Распознавание рукописного текста / Н.П.Гайдуков [Електронний ресурс]. - Режим доступу: http://masters.donntu.ru/2012/fknt/gaydukov/diss/index.htm
- Личканенко И.С. Методы обработки изображений и распознавания образов для задачи обнаружения номерных знаков транспортных средств / И.С.Личканенко, В.Н.Пчелкин [Електронний ресурс]. - Режим доступу: http://masters.donntu.ru/2013/fknt/lichkanenko/library/article1.htm
- Личканенко И.С. Исследование методов и поиск эффективного алгоритма для задачи распознавания номерных знаков транспортных средств / И.С.Личканенко [Електронний ресурс]. - Режим доступу: http://masters.donntu.ru/2013/fknt/lichkanenko/diss/index.htm
- Лащенко К.С. Разработка программного обеспечения для распознавания печатного текста дореволюционной русской орфографии / К.С.Лащенко [Електронний ресурс]. - Режим доступу: http://masters.donntu.ru/2017/fknt/lashchenko/diss/index.htm
- Мисюрёв А.В. Использование искусственных нейронных сетей для распознавания рукопечатных символов / А.В.Мисюрёв [Електронний ресурс]. - Режим доступу: http://ocrai.narod.ru/hp.html